认识 KEDA
什么是 KEDA ?
KEDA (Kubernetes-based Event-Driven Autoscaler) 是在 Kubernetes 中事件驱动的弹性伸缩器,功能非常强大。不仅支持根据基础的 CPU 和内存指标进行伸缩,还支持根据各种消息队列中的长度、数据库中的数据统计、QPS、Cron 定时计划以及您可以想象的任何其他指标进行伸缩,甚至还可以将副本缩到 0。
该项目于 2020.3 被 CNCF 接收,2021.8 开始孵化,最后在 2023.8 宣布毕业,目前已经非常成熟,可放心在生产环境中使用。
为什么需要 KEDA ?
HPA 是 Kubernetes 自带的 Pod 水平自动伸缩器,只能根据监控指标对工作负载自动扩缩容,指标主要是工作负载的 CPU 和内存的利用率(Resource Metrics),如果需要支持其它自定义指标,一般是安装 prometheus-adapter 来作为 HPA 的 Custom Metrics 和 External Metrics 的实现来将 Prometheus 中的监控数据作为自定义指标提供给 HPA。理论上,用 HPA + prometheus-adapter 也能实现 KEDA 的功能,但实现上会非常麻烦,比如想要根据数据库中任务表里记录的待执行的任务数量统计进行伸缩,就需要编写并部署 Exporter 应用,将统计结果转换为 Metrics 暴露给 Prometheus 进行采集,然后 prometheus-adapter 再从 Prometheus 查询待执行的任务数量指标来决定是否伸缩。
KEDA 的出现主要是为了解决 HPA 无法基于灵活的事件源进行伸缩的这个问题,内置了几十种常见的 Scaler ,可直接跟各种第三方应用对接,比如各种开源和云托管的关系型数据库、时序数据库、文档数据库、键值存储、消息队列、事件总线等,也可以使用 Cron 表达式进行定时自动伸缩,常见的伸缩常见基本都涵盖了,如果发现有不支持的,还可以自己实现一个外部 Scaler 来配合 KEDA 使用。
KEDA 的原理
KEDA 并不是要替代 HPA,而是作为 HPA 的补充或者增强,事实上很多时候 KEDA 是配合 HPA 一起工作的,这是 KEDA 官方的架构图:
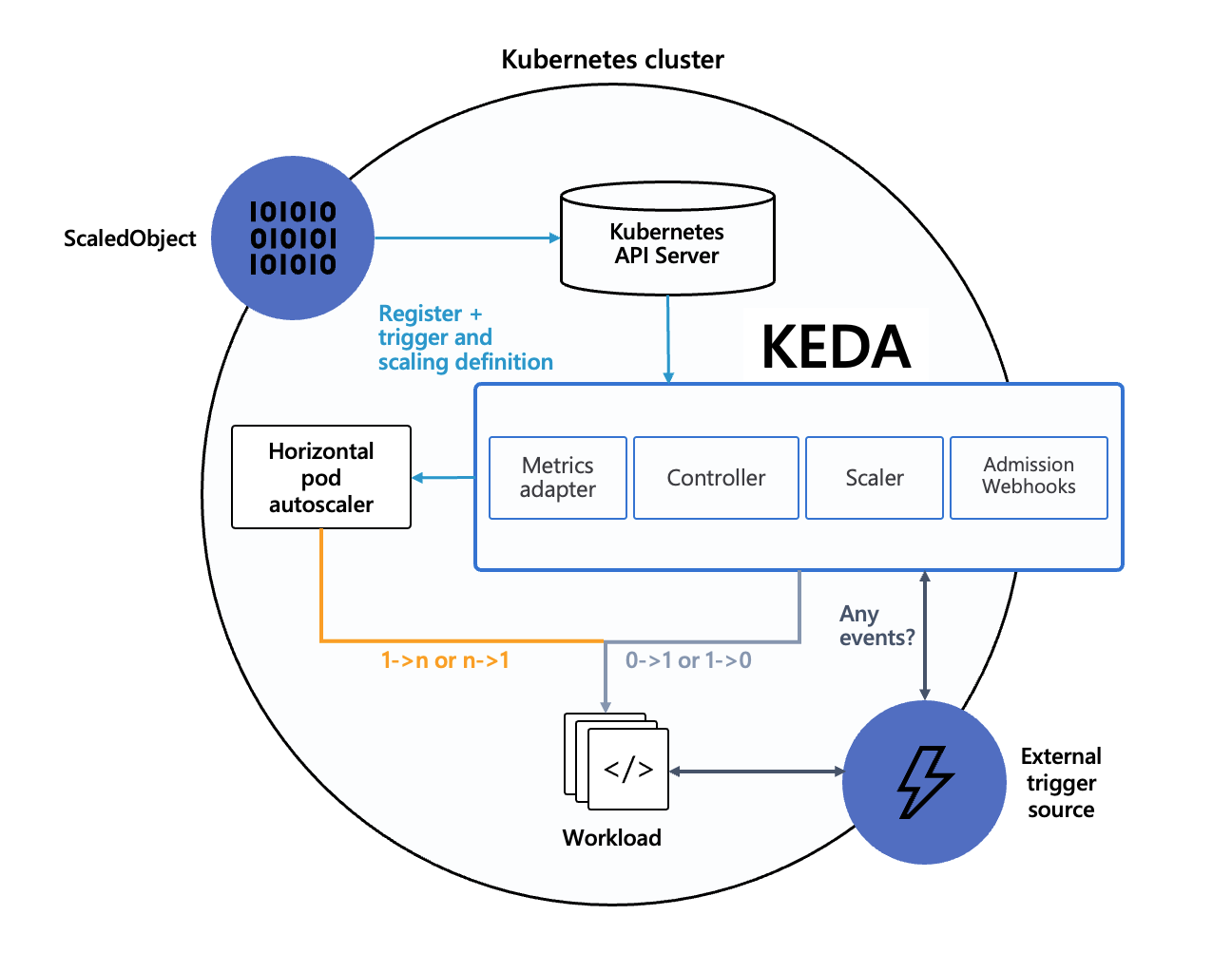
- 当要将工作负载的副本数缩到闲时副本数,或从闲时副本数扩容时,由 KEDA 通过修改工作负载的副本数实现(闲时副本数小于
minReplicaCount,包括 0,即可以缩到 0)。 - 其它情况下的扩缩容由 HPA 实现,HPA 由 KEDA 自动管理,HPA 使用 External Metrics 作为数据源,而 External Metrics 后端的数据由 KEDA 提供。
- KEDA 各种 Scalers 的核心其实就是为 HPA 暴露 External Metrics 格式的数据,KEDA 会将各种外部事件转换为所需的 External Metrics 数据,最终实现 HPA 通过 External Metrics 数据进行自动伸缩,直接复用了 HPA 已有的能力,所以如果还想要控制扩缩容的行为细节(比如快速扩容,缓慢缩容),可以直接通过配置 HPA 的
behavior字段来实现 (要求 Kubernetes 版本 >= 1.18)。
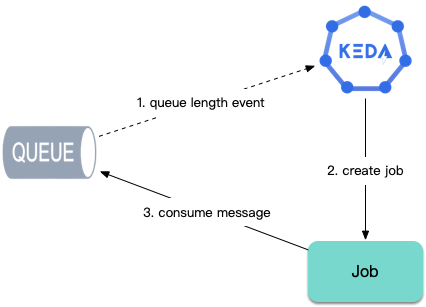
除了工作负载的扩缩容,对于任务计算类场景,KEDA 还可以根据排队的任务数量自动创建 Job 来实现对任务的及时处理:
哪些场景适合使用 KEDA ?
下面罗列下适合使用 KEDA 的场景。
微服务多级调用
在微服务中,基本都存在多级调用的业务场景,压力是逐级传递的,下面展示了一个常见的情况:

如果使用传统的 HPA 根据负载扩缩容,用户流量进入集群后:
Deploy A负载升高,指标变化迫使Deploy A扩容。- A 扩容之后,吞吐量变大,B 受到压力,再次采集到指标变化,扩容
Deploy B。 - B 吞吐变大,C 受到压力,扩容
Deploy C。
这个逐级传递的过程不仅缓慢,还很危险:每一级的扩容都是直接被 CPU 或内存的飙高触发的,被 “冲垮” 的可能性是普遍存在的。这种被动、滞后的方式,很明显是有问题的。
此时,我们可以利用 KEDA 来实现多级快速扩容:
Deploy A可根据自身负载或网关记录的 QPS 等指标扩缩容。Deploy B和Deploy C可根据Deploy A副本数扩缩容(各级服务副本数保持一定比例)。
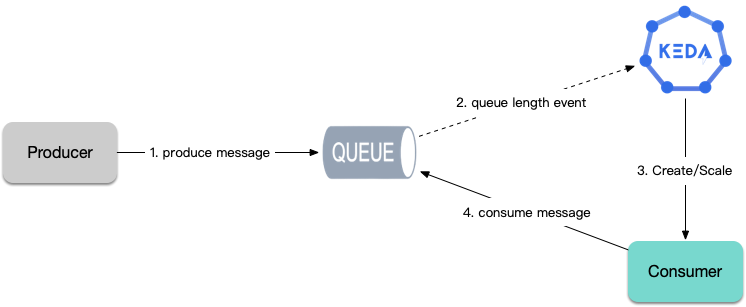
任务执行(生产者与消费者)
如果有需要长时间执行的计算任务,如数据分析、ETL、机器学习等场景,从消息队列或数据库中取任务进行执行,需要根据任务数量来伸缩,使用 HPA 不太合适,用 KEDA 就非常方便,可以让 KEDA 根据排队中的任务数量对工作负载进行伸缩,也可以自动创建 Job 来消费任务。
周期性规律
如果业务有周期性的波峰波谷特征,可以使用 KEDA 配置定时伸缩,在波峰来临之前先提前扩容,结束之后再缓慢缩容。