部署大模型常见问题
CUDA、GPU 驱动、PyTorch、大模型兼容性问题
通常 Ollama 和 vLLM 官方的 latest 容器镜像中的 CUDA 版本能兼容很大部分 GPU 卡和驱动,但要将大模型顺利跑起来,跟 CUDA、GPU卡及其驱动、PyTorch(vLLM)以及大模型本身都可能有关系,很难枚举所有情况,特别是 vLLM,并不是所有大模型都支持,且依赖 PyTorch,而不同 PyTorch 版本能兼容的 CUDA 版本也不一样,不同 CUDA 版本能兼容的 GPU 驱动版本也不一样。
vLLM 启动或运行过程中可能报错,如:
- 报错1
- 报错2
- 报错3
- 报错4
Traceback (most recent call last):
File "/usr/local/bin/vllm", line 8, in <module>
sys.exit(main())
^^^^^^
File "/usr/local/lib/python3.12/dist-packages/vllm/scripts.py", line 204, in main
args.dispatch_function(args)
File "/usr/local/lib/python3.12/dist-packages/vllm/scripts.py", line 44, in serve
uvloop.run(run_server(args))
File "/usr/local/lib/python3.12/dist-packages/uvloop/__init__.py", line 109, in run
return __asyncio.run(
^^^^^^^^^^^^^^
File "/usr/lib/python3.12/asyncio/runners.py", line 195, in run
return runner.run(main)
^^^^^^^^^^^^^^^^
File "/usr/lib/python3.12/asyncio/runners.py", line 118, in run
return self._loop.run_until_complete(task)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "uvloop/loop.pyx", line 1518, in uvloop.loop.Loop.run_until_complete
File "/usr/local/lib/python3.12/dist-packages/uvloop/__init__.py", line 61, in wrapper
return await main
^^^^^^^^^^
File "/usr/local/lib/python3.12/dist-packages/vllm/entrypoints/openai/api_server.py", line 875, in run_server
async with build_async_engine_client(args) as engine_client:
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/lib/python3.12/contextlib.py", line 210, in __aenter__
return await anext(self.gen)
^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.12/dist-packages/vllm/entrypoints/openai/api_server.py", line 136, in build_async_engine_client
async with build_async_engine_client_from_engine_args(
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/lib/python3.12/contextlib.py", line 210, in __aenter__
return await anext(self.gen)
^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.12/dist-packages/vllm/entrypoints/openai/api_server.py", line 230, in build_async_engine_client_from_engine_args
raise RuntimeError(
RuntimeError: Engine process failed to start. See stack trace for the root cause.
ERROR 02-07 02:51:31 client.py:300] RuntimeError('Engine process (pid 20) died.')
ERROR 02-07 02:51:31 client.py:300] NoneType: None
ERROR 02-07 02:51:34 serving_chat.py:661] Error in chat completion stream generator.
ERROR 02-07 02:51:34 serving_chat.py:661] Traceback (most recent call last):
ERROR 02-07 02:51:34 serving_chat.py:661] File "/usr/local/lib/python3.12/dist-packages/vllm/entrypoints/openai/serving_chat.py", line 359, in chat_completion_stream_generator
ERROR 02-07 02:51:34 serving_chat.py:661] async for res in result_generator:
ERROR 02-07 02:51:34 serving_chat.py:661] File "/usr/local/lib/python3.12/dist-packages/vllm/engine/multiprocessing/client.py", line 658, in _process_request
ERROR 02-07 02:51:34 serving_chat.py:661] raise request_output
ERROR 02-07 02:51:34 serving_chat.py:661] vllm.engine.multiprocessing.MQEngineDeadError: Engine loop is not running. Inspect the stacktrace to find the original error: RuntimeError('Engine process (pid 20) died.').
CRITICAL 02-07 02:51:34 launcher.py:101] MQLLMEngine is already dead, terminating server process
INFO: Shutting down
INFO: Waiting for application shutdown.
INFO: Application shutdown complete.
INFO: Finished server process [1]
RuntimeError: The NVIDIA driver on your system is too old (found version 11080). Please update your GPU driver by downloading and installing a new version from the URL: http://www.nvidia.com/Download/index.aspx Alternatively, go to: https://pytorch.org to install a PyTorch version that has been compiled with your version of the CUDA driver.
Traceback (most recent call last):
File "/usr/local/bin/vllm", line 8, in <module>
sys.exit(main())
^^^^^^
File "/usr/local/lib/python3.12/dist-packages/vllm/scripts.py", line 204, in main
args.dispatch_function(args)
File "/usr/local/lib/python3.12/dist-packages/vllm/scripts.py", line 44, in serve
uvloop.run(run_server(args))
File "/usr/local/lib/python3.12/dist-packages/uvloop/__init__.py", line 109, in run
return __asyncio.run(
^^^^^^^^^^^^^^
File "/usr/lib/python3.12/asyncio/runners.py", line 195, in run
return runner.run(main)
^^^^^^^^^^^^^^^^
File "/usr/lib/python3.12/asyncio/runners.py", line 118, in run
return self._loop.run_until_complete(task)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "uvloop/loop.pyx", line 1518, in uvloop.loop.Loop.run_until_complete
File "/usr/local/lib/python3.12/dist-packages/uvloop/__init__.py", line 61, in wrapper
return await main
^^^^^^^^^^
File "/usr/local/lib/python3.12/dist-packages/vllm/entrypoints/openai/api_server.py", line 875, in run_server
async with build_async_engine_client(args) as engine_client:
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/lib/python3.12/contextlib.py", line 210, in __aenter__
return await anext(self.gen)
^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.12/dist-packages/vllm/entrypoints/openai/api_server.py", line 136, in build_async_engine_client
async with build_async_engine_client_from_engine_args(
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/lib/python3.12/contextlib.py", line 210, in __aenter__
return await anext(self.gen)
^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.12/dist-packages/vllm/entrypoints/openai/api_server.py", line 230, in build_async_engine_client_from_engine_args
raise RuntimeError(
RuntimeError: Engine process failed to start. See stack trace for the root cause.
ERROR 02-06 23:41:11 engine.py:389] RuntimeError: CUDA error: no kernel image is available for execution on the device
ERROR 02-06 23:41:11 engine.py:389] CUDA kernel errors might be asynchronously reported at some other API call, so the stacktrace below might be incorrect.
ERROR 02-06 23:41:11 engine.py:389] For debugging consider passing CUDA_LAUNCH_BLOCKING=1
ERROR 02-06 23:41:11 engine.py:389] Compile with `TORCH_USE_CUDA_DSA` to enable device-side assertions.
ERROR 02-06 23:41:11 engine.py:389]
Traceback (most recent call last):
File "/usr/lib/python3.12/multiprocessing/process.py", line 314, in _bootstrap
self.run()
File "/usr/lib/python3.12/multiprocessing/process.py", line 108, in run
self._target(*self._args, **self._kwargs)
File "/usr/local/lib/python3.12/dist-packages/vllm/engine/multiprocessing/engine.py", line 391, in run_mp_engine
raise e
File "/usr/local/lib/python3.12/dist-packages/vllm/engine/multiprocessing/engine.py", line 380, in run_mp_engine
engine = MQLLMEngine.from_engine_args(engine_args=engine_args,
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.12/dist-packages/vllm/engine/multiprocessing/engine.py", line 123, in from_engine_args
return cls(ipc_path=ipc_path,
^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.12/dist-packages/vllm/engine/multiprocessing/engine.py", line 75, in __init__
self.engine = LLMEngine(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.12/dist-packages/vllm/engine/llm_engine.py", line 276, in __init__
self._initialize_kv_caches()
File "/usr/local/lib/python3.12/dist-packages/vllm/engine/llm_engine.py", line 416, in _initialize_kv_caches
self.model_executor.determine_num_available_blocks())
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.12/dist-packages/vllm/executor/executor_base.py", line 101, in determine_num_available_blocks
results = self.collective_rpc("determine_num_available_blocks")
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.12/dist-packages/vllm/executor/uniproc_executor.py", line 51, in collective_rpc
answer = run_method(self.driver_worker, method, args, kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.12/dist-packages/vllm/utils.py", line 2220, in run_method
return func(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.12/dist-packages/torch/utils/_contextlib.py", line 116, in decorate_context
return func(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.12/dist-packages/vllm/worker/worker.py", line 229, in determine_num_available_blocks
self.model_runner.profile_run()
File "/usr/local/lib/python3.12/dist-packages/torch/utils/_contextlib.py", line 116, in decorate_context
return func(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.12/dist-packages/vllm/worker/model_runner.py", line 1235, in profile_run
self._dummy_run(max_num_batched_tokens, max_num_seqs)
File "/usr/local/lib/python3.12/dist-packages/vllm/worker/model_runner.py", line 1346, in _dummy_run
self.execute_model(model_input, kv_caches, intermediate_tensors)
File "/usr/local/lib/python3.12/dist-packages/torch/utils/_contextlib.py", line 116, in decorate_context
return func(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.12/dist-packages/vllm/worker/model_runner.py", line 1719, in execute_model
hidden_or_intermediate_states = model_executable(
^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.12/dist-packages/torch/nn/modules/module.py", line 1736, in _wrapped_call_impl
return self._call_impl(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.12/dist-packages/torch/nn/modules/module.py", line 1747, in _call_impl
return forward_call(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.12/dist-packages/vllm/model_executor/models/qwen2.py", line 486, in forward
hidden_states = self.model(input_ids, positions, kv_caches,
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.12/dist-packages/vllm/compilation/decorators.py", line 172, in __call__
return self.forward(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.12/dist-packages/vllm/model_executor/models/qwen2.py", line 348, in forward
hidden_states, residual = layer(
^^^^^^
File "/usr/local/lib/python3.12/dist-packages/torch/nn/modules/module.py", line 1736, in _wrapped_call_impl
return self._call_impl(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.12/dist-packages/torch/nn/modules/module.py", line 1747, in _call_impl
return forward_call(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.12/dist-packages/vllm/model_executor/models/qwen2.py", line 247, in forward
hidden_states = self.self_attn(
^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.12/dist-packages/torch/nn/modules/module.py", line 1736, in _wrapped_call_impl
return self._call_impl(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.12/dist-packages/torch/nn/modules/module.py", line 1747, in _call_impl
return forward_call(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.12/dist-packages/vllm/model_executor/models/qwen2.py", line 176, in forward
qkv, _ = self.qkv_proj(hidden_states)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.12/dist-packages/torch/nn/modules/module.py", line 1736, in _wrapped_call_impl
return self._call_impl(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.12/dist-packages/torch/nn/modules/module.py", line 1747, in _call_impl
return forward_call(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.12/dist-packages/vllm/model_executor/layers/linear.py", line 382, in forward
output_parallel = self.quant_method.apply(self, input_, bias)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.12/dist-packages/vllm/model_executor/layers/linear.py", line 142, in apply
return F.linear(x, layer.weight, bias)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
RuntimeError: CUDA error: no kernel image is available for execution on the device
CUDA kernel errors might be asynchronously reported at some other API call, so the stacktrace below might be incorrect.
For debugging consider passing CUDA_LAUNCH_BLOCKING=1
Compile with `TORCH_USE_CUDA_DSA` to enable device-side assertions.
[rank0]:[W206 23:41:12.978693132 ProcessGroupNCCL.cpp:1250] Warning: WARNING: process group has NOT been destroyed before we destruct ProcessGroupNCCL. On normal program exit, the application should call destroy_process_group to ensure that any pending NCCL operations have finished in this process. In rare cases this process can exit before this point and block the progress of another member of the process group. This constraint has always been present, but this warning has only been added since PyTorch 2.4 (function operator())
Traceback (most recent call last):
File "/usr/local/bin/vllm", line 8, in <module>
sys.exit(main())
^^^^^^
File "/usr/local/lib/python3.12/dist-packages/vllm/scripts.py", line 204, in main
args.dispatch_function(args)
File "/usr/local/lib/python3.12/dist-packages/vllm/scripts.py", line 44, in serve
uvloop.run(run_server(args))
File "/usr/local/lib/python3.12/dist-packages/uvloop/__init__.py", line 109, in run
return __asyncio.run(
^^^^^^^^^^^^^^
File "/usr/lib/python3.12/asyncio/runners.py", line 195, in run
return runner.run(main)
^^^^^^^^^^^^^^^^
File "/usr/lib/python3.12/asyncio/runners.py", line 118, in run
return self._loop.run_until_complete(task)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "uvloop/loop.pyx", line 1518, in uvloop.loop.Loop.run_until_complete
File "/usr/local/lib/python3.12/dist-packages/uvloop/__init__.py", line 61, in wrapper
return await main
^^^^^^^^^^
File "/usr/local/lib/python3.12/dist-packages/vllm/entrypoints/openai/api_server.py", line 875, in run_server
async with build_async_engine_client(args) as engine_client:
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/lib/python3.12/contextlib.py", line 210, in __aenter__
return await anext(self.gen)
^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.12/dist-packages/vllm/entrypoints/openai/api_server.py", line 136, in build_async_engine_client
async with build_async_engine_client_from_engine_args(
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/lib/python3.12/contextlib.py", line 210, in __aenter__
return await anext(self.gen)
^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.12/dist-packages/vllm/entrypoints/openai/api_server.py", line 230, in build_async_engine_client_from_engine_args
raise RuntimeError(
RuntimeError: Engine process failed to start. See stack trace for the root cause.
遇到这些情况建议是先调研和确认下各种版本信息,看能否兼容。不行则尝试换 GPU 卡或换 CUDA 版本(GPU 驱动是自动装的,一般无法改变),下面有如何指定最佳 CUDA 版本的方法。
如何指定最佳的 CUDA 版本?
如果希望精确控制 CUDA 版本以达到最佳效果或规避一些兼容性问题,可按照下面的方法来指定最佳的 CUDA 版本。
步骤1: 确认 GPU 驱动和所需 CUDA 版本
确认 GPU 驱动版本:
- 如果是普通节点或原生节点,在创建节点池选机型,勾选
后台自动安装GPU驱动的时候就会提示 GPU 驱动版本,如果没有也可以登录节点执行nvidia-smni查看。 - 如果调度到超级节点,可进入 Pod 执行
nvidia-smi命令查看 GPU 驱动版本。
确认 CUDA 版本:在 NVIDIA 官网的 CUDA Toolkit and Corresponding Driver Versions 中,查找适合前面确认到的 GPU 驱动版本的 CUDA 版本,用于后面打包镜像时选择对应版本的基础镜像。
步骤2: 编译 Ollama、vLLM 或 SGLang 镜像
Ollama 镜像
如果使用 Ollama 运行大模型,按照下面的方法编译指定 CUDA 版本的 Ollama 镜像。
准备 Dockerfile:
FROM nvidia/cuda:11.8.0-cudnn8-runtime-ubuntu22.04
RUN apt update -y && apt install -y curl
RUN curl -fsSL https://ollama.com/install.sh | sh
基础镜像使用
nvidia/cuda,具体使用哪个 tag 可根据前面确认的 cuda 版本来定。这里 是所有 tag 的列表。
编译并上传镜像:
docker build -t ccr.ccs.tencentyun.com/imroc/ollama:cuda11.8-ubuntu22.04 .
docker push ccr.ccs.tencentyun.com/imroc/ollama:cuda11.8-ubuntu22.04
注意修改成自己的镜像名称。
vLLM 镜像
如果使用 vLLM 运行大模型,按照下面的方法编译指定 CUDA 版本的 vLLM 镜像。
- 克隆 vLLM 仓库:
git clone --depth=1 https://github.com/vllm-project/vllm.git
- 指定 CUDA 版本并编译上传:
cd vllm
docker build --build-arg CUDA_VERSION=12.4.1 -t ccr.ccs.tencentyun.com/imroc/vllm-openai:cuda-12.4.1 .
docker push ccr.ccs.tencentyun.com/imroc/vllm-openai:cuda-12.4.1
通过
CUDA_VERSION参数指定 CUDA 版本;注意替换成自己的镜像名称。
该方法只使用 CUDA 版本的微调,不要跨大版本,比如官方 Dockerfile 中使用的 CUDA_VERSION 是 12.x,那么指定的 CUDA_VERSION 就不要低于 12,因为 vLLM、PyTorch、CUDA 这几个的版本需要在兼容范围内,否则会有兼容性问题。如要编译更低版本的 CUDA,建议参考官方文档的方法(通过 pip 命令安装低版本编译好的 vLLM 二进制),然后编写相应的 Dockerfile 来编译镜像。
SGLang 镜像
SGLang 官方镜像提供了各个 CUDA 版本,修改镜像 tag 即可,可选 tag 列表在 这里 搜索。
如果没有期望的,可以参考以下类似 vLLM 的方式自行编译。
- 克隆 SGLang 仓库:
git clone --depth=1 https://github.com/sgl-project/sglang.git
- 指定 CUDA 版本并编译上传:
cd sglang/docker
docker build --build-arg CUDA_VERSION=12.4.1 -t ccr.ccs.tencentyun.com/imroc/sglang:cuda-12.4.1 .
docker push ccr.ccs.tencentyun.com/imroc/sglang:cuda-12.4.1
通过
CUDA_VERSION参数指定 CUDA 版本;注意替换成自己的镜像名称。
步骤3: 替换镜像
最后在部署 Ollama、vLLM 或 SGLang 的 Deployment 中,将镜像替换成自己指定了 CUDA 版本编译上传的镜像名称,即可完成指定最佳的 CUDA 版本。
模型为何下载失败?
通常是没有开公网,下面是开通公网的方法。
如果使用普通节点或原生节点,可以在创建节点池的时候指定公网带宽:
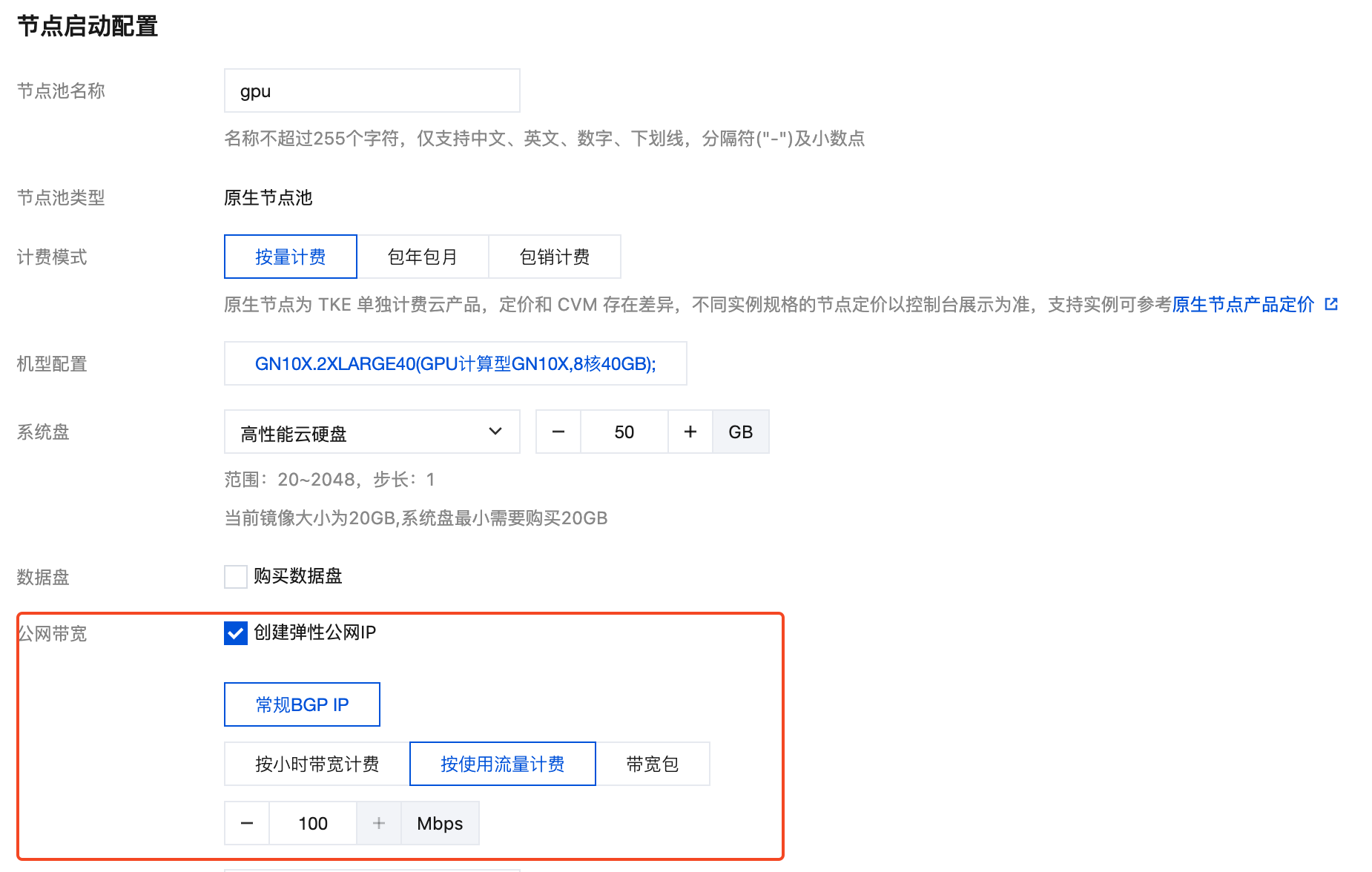
如果使用超级节点,Pod 默认没有公网,可以使用 NAT 网关来访问外网,详情请参考 通过 NAT 网关访问外网,当然这个也适用于普通节点和原生节点。
如何使用超过 2T 的系统盘?
如果出于成本和性能的权衡考虑,或者测试阶段先不引入 CFS,降低复杂度,希望直接用本地系统盘存储大模型,而大模型占用又空间太大,希望能用超过 2T 的系统盘,则需要操作系统支持才可以,名称中带 UEFI 字样的系统镜像才支持超过 2T 的系统盘,默认不可用,如有需要可联系官方开通使用。
如何实现多卡并行?
Ollama、vLLM 和 SGLang 默认将模型部署到单张 GPU 卡上,如果是多人使用,并发请求,或者模型太大,可以配置下 Ollama 和 vLLM,将模型部署到多张 GPU 卡上并行计算来提升推理速度和吞吐量。
首先在定义 Ollama 或 vLLM 的 Deployment 时,需声明 GPU 的数量大于 1,示例:
resources:
requests:
nvidia.com/gpu: "2"
limits:
nvidia.com/gpu: "2"
对于 Ollama, 指定环境变量 OLLAMA_SCHED_SPREAD 为 1 表示将模型部署到所有 GPU 卡上,示例:
env:
- name: OLLAMA_SCHED_SPREAD # 多卡部署
value: "1"
对于 vLLM, 则需显式指定 --tensor-parallel-size 参数,表示将模型部署到多少张 GPU 卡上,示例:
command:
- bash
- -c
- |
set -ex
exec vllm serve /data/DeepSeek-R1-Distill-Qwen-7B \
--served-model-name DeepSeek-R1-Distill-Qwen-7B \
--host 0.0.0.0 --port 8000 \
--trust-remote-code \
--enable-chunked-prefill \
--max_num_batched_tokens 1024 \
--max_model_len 1024 \
--tensor-parallel-size 2 # 指定 N 张卡并行,与 requests 中指定的 GPU 数量一致
对于 SGLang,与 vLLM 类似,显式指定 --tp 参数,表示将模型部署到多少张卡上 GPU 卡上,示例:
command:
- bash
- -c
- |
set -x
exec python3 -m sglang.launch_server \
--host 0.0.0.0 \
--port 30000 \
--model-path /data/$LLM_MODEL \
--tp 4
如何实现多机分布式部署?
前面说的多卡部署仅限单台机器内的多卡,如果单个模型实在太大,而单台机器的 GPU 推理太慢,可以考虑用多机多卡分布式部署。
如何做到多机部署?如果只是简单增加副本数,各个节点的 GPU 并不能协同处理同一个任务,只能提升并发量,不能提升单个任务的推理速度。下面给出实现多机多卡分布式部署的思路,具体方案可参考相关链接,结合本文给出的示例 YAML 并进行相关修改。
- vLLM 官方支持通过 Ray 实现多机分布式部署,参考 Running vLLM on multiple nodes 和 Deploy Distributed Inference Service with vLLM and LWS on GPUs。
- SGLang 官方支持多机分布式部署,参考 Run Multi-Node Inference。
- Ollama 官方不支持多机分布式部署,但 llama.cpp 给出了一些支持,参考 issue Llama.cpp now supports distributed inference across multiple machines. (门槛较高)。
vLLM 多机部署
对于 vLLM 来说,在 Kubernetes 环境中推荐使用 lws 来实现多机分布式部署,下面给出部署实例。
首先,按照 lws 官方文档 安装 lws 到集群,需要注意的是,默认使用镜像是 registry.k8s.io/lws/lws,这个在国内环境下载不了,需修改 Deployment 的镜像地址为 docker.io/k8smirror/lws,该镜像为 lws 在 DockerHub 上的 mirror 镜像,长期自动同步,可放心使用(TKE 环境可直接拉取 DockerHub 的镜像)。
然后,下载 ray_init.sh 脚本,制作 vLLM+Ray 的镜像:
FROM docker.io/vllm/vllm-openai:latest
COPY ray_init.sh /vllm-workspace/ray_init.sh
RUN chmod +x /vllm-workspace/ray_init.sh
编译镜像并推送到镜像仓库:
docker build -t ccr.ccs.tencentyun.com/imroc/vllm-lws:latest .
docker push ccr.ccs.tencentyun.com/imroc/vllm-lws:latest
然后编写 LeaderWorkerSet 的 YAML 文件并将其部署到集群中:
这里假设每台 GPU 节点至少有 2 张 GPU 算卡,每个 Pod 使用 2 张卡,leader + worker 一共 2 个 Pod。
apiVersion: leaderworkerset.x-k8s.io/v1
kind: LeaderWorkerSet
metadata:
name: vllm
spec:
replicas: 1
leaderWorkerTemplate:
size: 2
restartPolicy: RecreateGroupOnPodRestart
leaderTemplate:
metadata:
labels:
role: leader
spec:
containers:
- name: vllm-leader
image: ccr.ccs.tencentyun.com/imroc/vllm-lws:latest
env:
- name: RAY_CLUSTER_SIZE
valueFrom:
fieldRef:
fieldPath: metadata.annotations['leaderworkerset.sigs.k8s.io/size']
command:
- sh
- -c
- |
/vllm-workspace/ray_init.sh leader --ray_cluster_size=$RAY_CLUSTER_SIZE
python3 -m vllm.entrypoints.openai.api_server \
--port 8000 \
--model /data/DeepSeek-R1-Distill-Qwen-32B \
--served-model-name DeepSeek-R1-Distill-Qwen-32B \
--tensor-parallel-size 2 \
--pipeline-parallel-size 2 \
--enforce-eager
resources:
limits:
nvidia.com/gpu: "2"
ports:
- containerPort: 8000
readinessProbe:
tcpSocket:
port: 8000
initialDelaySeconds: 15
periodSeconds: 10
volumeMounts:
- mountPath: /dev/shm
name: dshm
- mountPath: /data
name: data
volumes:
- name: dshm
emptyDir:
medium: Memory
sizeLimit: 15Gi
- name: data
persistentVolumeClaim:
claimName: ai-model
workerTemplate:
spec:
containers:
- name: vllm-worker
image: ccr.ccs.tencentyun.com/imroc/vllm-lws:latest
command:
- sh
- -c
- "/vllm-workspace/ray_init.sh worker --ray_address=$(LWS_LEADER_ADDRESS)"
resources:
limits:
nvidia.com/gpu: "2"
volumeMounts:
- mountPath: /dev/shm
name: dshm
- mountPath: /data
name: data
volumes:
- name: dshm
emptyDir:
medium: Memory
sizeLimit: 15Gi
- name: data
persistentVolumeClaim:
claimName: ai-model
---
apiVersion: v1
kind: Service
metadata:
name: vllm-api
spec:
ports:
- name: http
port: 8000
protocol: TCP
targetPort: 8000
selector:
leaderworkerset.sigs.k8s.io/name: vllm
role: leader
type: ClusterIP
nvidia.com/gpu和--tensor-parallel-size指定每台节点有多少张 GPU 卡。--pipeline-parallel-size指定有多少台节点。--model指定模型文件在容器内的路径。--served-model-name指定模型名称。
Pod 成功跑起来后进入 leader Pod:
kubectl exec -it vllm-0 -- bash
测试 API:
curl -v http://127.0.0.1:8000/v1/completions -H "Content-Type: application/json" -d '{
"model": "DeepSeek-R1-Distill-Qwen-32B",
"prompt": "你是谁?",
"max_tokens": 100,
"temperature": 0
}'
如果部署了 OpenWebUI,确保 OPENAI_API_BASE_URL 指向上面示例 YAML 中 Service 的地址,如 http://vllm-api:8000/v1。
SGLang 多机部署
对于 SGLang 来说,官方没有给出在 Kubernetes 上多机部署的方案和实例,但我们可以参考 Example: Serving with two H200*8 nodes and docker 这个官方例子,将其转化为 StatefulSet 和 LeaderWorkerSet 方式进行部署,最佳实践推荐使用 LeaderWorkerSet 部署(需安装 lws 组件) 。
以下是 2 个 4 卡 GPU 节点组成的 GPU 集群的例子:
- StatefulSet 方式部署
- LeaderWorkerSet 方式部署
用 Statefulset 部署无需引入 lws 依赖,但扩容 GPU 集群时有点麻烦,需手动创建新的 Statefulset。
根据实际情况修改:
nvidia.com/gpu为每个节点的 GPU 卡数。replicas为 GPU 集群的总节点数,需REPLICAS环境变量的值保持一致。LLM_MODEL环境变量为模型名称,与前面下载 Job 中指定的名称一致。TOTAL_GPU环境变量为总 GPU 卡数,等于每个节点的 GPU 数量乘以节点数。STATEFULSET_NAME环境变量的值StatefulSet实际名称保持一致。SERVICE_NAME环境变量的值与StatefulSet中指定的serviceName,以及实际的 Service 的名称保持一致。- 如果部署了 OpenWebUI,确保
OPENAI_API_BASE_URL指向第一个副本的地址(leader),如http://sglang-0.sglang:3000/v1。
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: sglang
spec:
selector:
matchLabels:
app: sglang
serviceName: sglang
replicas: 2
template:
metadata:
labels:
app: sglang
spec:
containers:
- name: sglang
image: lmsysorg/sglang:latest
env:
- name: LLM_MODEL
value: deepseek-ai/DeepSeek-R1-Distill-Qwen-32B
- name: TOTAL_GPU
value: "8"
- name: REPLICAS
value: "2"
- name: STATEFULSET_NAME
value: "sglang"
- name: SERVICE_NAME
value: "sglang"
- name: ORDINAL_NUMBER
valueFrom:
fieldRef:
fieldPath: metadata.labels['apps.kubernetes.io/pod-index']
ports:
- containerPort: 30000
resources:
limits:
nvidia.com/gpu: "4"
command:
- bash
- -c
- |
if [[ "$ORDINAL_NUMBER" == "0" ]]; then
python3 -m sglang.launch_server --model-path /data/$LLM_MODEL --tp $TOTAL_GPU --dist-init-addr $STATEFULSET_NAME-0.$SERVICE_NAME:5000 --nnodes $REPLICAS --node-rank $ORDINAL_NUMBER --trust-remote-code --host 0.0.0.0 --port 30000
else
python3 -m sglang.launch_server --model-path /data/$LLM_MODEL --tp $TOTAL_GPU --dist-init-addr $STATEFULSET_NAME-0.$SERVICE_NAME:5000 --nnodes $REPLICAS --node-rank $ORDINAL_NUMBER --trust-remote-code
fi
volumeMounts:
- name: data
mountPath: /data
- name: shm
mountPath: /dev/shm
volumes:
- name: data
persistentVolumeClaim:
claimName: ai-model
- name: shm
emptyDir:
medium: Memory
sizeLimit: 40Gi
---
apiVersion: v1
kind: Service
metadata:
name: sglang
spec:
selector:
app: sglang
type: ClusterIP
clusterIP: None
ports:
- name: api
protocol: TCP
port: 30000
targetPort: 30000
使用 LeaderWorkerSet 部署的前提需在集群中安装 lws 组件,可按照 lws 官方文档 安装 lws 到集群,需要注意的是,默认使用镜像是 registry.k8s.io/lws/lws,这个在国内环境下载不了,需修改 Deployment 的镜像地址为 docker.io/k8smirror/lws,该镜像为 lws 在 DockerHub 上的 mirror 镜像,长期自动同步,可放心使用(TKE 环境可直接拉取 DockerHub 的镜像)。
根据实际情况修改 YAML 中的一些配置:
nvidia.com/gpu为每个节点的 GPU 卡数。--tp为总 GPU 卡数,等于每个节点的 GPU 数量乘以节点数。--model-path模型加载的目录。
apiVersion: leaderworkerset.x-k8s.io/v1
kind: LeaderWorkerSet
metadata:
name: sglang
spec:
replicas: 1
leaderWorkerTemplate:
size: 2
restartPolicy: RecreateGroupOnPodRestart
leaderTemplate:
metadata:
labels:
role: leader
spec:
containers:
- name: sglang-leader
image: lmsysorg/sglang:latest
command:
- bash
- -c
- |
set -x
exec python3 -m sglang.launch_server \
--model-path /data/deepseek-ai/DeepSeek-R1-Distill-Qwen-32B \
--nnodes $LWS_GROUP_SIZE \
--tp 8 \
--node-rank 0 \
--dist-init-addr $(LWS_LEADER_ADDRESS):5000 \
--trust-remote-code \
--host 0.0.0.0 \
--port 30000
resources:
limits:
nvidia.com/gpu: "4"
ports:
- containerPort: 30000
volumeMounts:
- mountPath: /dev/shm
name: dshm
- mountPath: /data
name: data
volumes:
- name: dshm
emptyDir:
medium: Memory
sizeLimit: 40Gi
- name: data
persistentVolumeClaim:
claimName: ai-model
workerTemplate:
spec:
containers:
- name: sglang-worker
image: lmsysorg/sglang:latest
env:
- name: ORDINAL_NUMBER
valueFrom:
fieldRef:
fieldPath: metadata.labels['apps.kubernetes.io/pod-index']
command:
- bash
- -c
- |
set -x
exec python3 -m sglang.launch_server \
--model-path /data/deepseek-ai/DeepSeek-R1-Distill-Qwen-32B \
--nnodes $LWS_GROUP_SIZE \
--tp 8 \
--node-rank $ORDINAL_NUMBER \
--dist-init-addr $(LWS_LEADER_ADDRESS):5000 \
--trust-remote-code
resources:
limits:
nvidia.com/gpu: "4"
volumeMounts:
- mountPath: /dev/shm
name: dshm
- mountPath: /data
name: data
volumes:
- name: dshm
emptyDir:
medium: Memory
sizeLimit: 40Gi
- name: data
persistentVolumeClaim:
claimName: ai-model
多机部署如何扩容 GPU?
分布式多机部署一般要求每台节点 GPU 数量一致,且要事先规划好总节点数量,然后根据这些信息配置启动参数(GPU 并行数量,总节点数量),如果要扩容,只能增加新的 GPU 集群,且让请求负载均衡到多个 GPU 集群。
以下是具体思路:
-
新增 GPU 集群:可以利用 lws 的能力,调整 replicas 的值,replicas + 1 表示新增一个 leader + worker 的集群,即扩容新的 GPU 集群。
-
多 GPU 集群负载均衡:可以新建一个 Service 选中多个不同 GPU 集群的 leader Pod 来实现,示例:
注意leaderworkerset.sigs.k8s.io/name指定 lws 的名称。- 所有 GPU 集群的 leader Pod 的 index 固定为 0,可以通过
apps.kubernetes.io/pod-index: "0"这个 label 来选中。 - 涉及 API 地址配置的地方(如 OpenWebUI),指向这个新 Service 的地址(如
http://vllm-leader:8000/v1)。
apiVersion: v1kind: Servicemetadata:name: vllm-leaderspec:type: ClusterIPselector:leaderworkerset.sigs.k8s.io/name: vllmapps.kubernetes.io/pod-index: "0"ports:- name: apiport: 8000targetPort: 8000
vLLM 报错 ValueError: invalid literal for int() with base 10: 'tcp://xxx.xx.xx.xx:8000'
vLLM 启动时报这个错:
ERROR 02-06 18:29:55 engine.py:389] ValueError: invalid literal for int() with base 10: 'tcp://172.16.168.90:8000'
Traceback (most recent call last):
File "/usr/lib/python3.12/multiprocessing/process.py", line 314, in _bootstrap
self.run()
File "/usr/lib/python3.12/multiprocessing/process.py", line 108, in run
self._target(*self._args, **self._kwargs)
File "/usr/local/lib/python3.12/dist-packages/vllm/engine/multiprocessing/engine.py", line 391, in run_mp_engine
raise e
File "/usr/local/lib/python3.12/dist-packages/vllm/engine/multiprocessing/engine.py", line 380, in run_mp_engine
engine = MQLLMEngine.from_engine_args(engine_args=engine_args,
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.12/dist-packages/vllm/engine/multiprocessing/engine.py", line 123, in from_engine_args
return cls(ipc_path=ipc_path,
^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.12/dist-packages/vllm/engine/multiprocessing/engine.py", line 75, in __init__
self.engine = LLMEngine(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.12/dist-packages/vllm/engine/llm_engine.py", line 273, in __init__
self.model_executor = executor_class(vllm_config=vllm_config, )
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.12/dist-packages/vllm/executor/executor_base.py", line 51, in __init__
self._init_executor()
File "/usr/local/lib/python3.12/dist-packages/vllm/executor/uniproc_executor.py", line 29, in _init_executor
get_ip(), get_open_port())
^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.12/dist-packages/vllm/utils.py", line 506, in get_open_port
port = envs.VLLM_PORT
^^^^^^^^^^^^^^
File "/usr/local/lib/python3.12/dist-packages/vllm/envs.py", line 583, in __getattr__
return environment_variables[name]()
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.12/dist-packages/vllm/envs.py", line 188, in <lambda>
lambda: int(os.getenv('VLLM_PORT', '0'))
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
- 原因:是用 DeepSeek 来帮忙分析得到灵感后发现的:关键点是
VLLM_PORT这个环境变量,vLLM 会解析这个环境变量,它期望是个数字但实际得到的不是所以才报错,但我没定义这个环境变量,这个环境变量是 K8S 根据 Service 自动生成注入到 Pod 中的。 - 解决办法:不要给 vLLM 的 Service 名称定义成
vllm,换成其它名字。
vLLM 报错 ValueError: Bfloat16 is only supported on GPUs with compute capability of at least 8.0.
vLLM 启动时报这个错:
ValueError: Bfloat16 is only supported on GPUs with compute capability of at least 8.0. Your Tesla V100-SXM2-32GB GPU has compute capability 7.0. You can use float16 instead by explicitly setting the`dtype` flag in CLI, for example: --dtype=half.
Traceback (most recent call last):
File "/usr/local/bin/vllm", line 8, in <module>
sys.exit(main())
^^^^^^
File "/usr/local/lib/python3.12/dist-packages/vllm/scripts.py", line 204, in main
args.dispatch_function(args)
File "/usr/local/lib/python3.12/dist-packages/vllm/scripts.py", line 44, in serve
uvloop.run(run_server(args))
File "/usr/local/lib/python3.12/dist-packages/uvloop/__init__.py", line 109, in run
return __asyncio.run(
^^^^^^^^^^^^^^
File "/usr/lib/python3.12/asyncio/runners.py", line 195, in run
return runner.run(main)
^^^^^^^^^^^^^^^^
File "/usr/lib/python3.12/asyncio/runners.py", line 118, in run
return self._loop.run_until_complete(task)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "uvloop/loop.pyx", line 1518, in uvloop.loop.Loop.run_until_complete
File "/usr/local/lib/python3.12/dist-packages/uvloop/__init__.py", line 61, in wrapper
return await main
^^^^^^^^^^
File "/usr/local/lib/python3.12/dist-packages/vllm/entrypoints/openai/api_server.py", line 875, in run_server
async with build_async_engine_client(args) as engine_client:
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/lib/python3.12/contextlib.py", line 210, in __aenter__
return await anext(self.gen)
^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.12/dist-packages/vllm/entrypoints/openai/api_server.py", line 136, in build_async_engine_client
async with build_async_engine_client_from_engine_args(
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/lib/python3.12/contextlib.py", line 210, in __aenter__
return await anext(self.gen)
^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.12/dist-packages/vllm/entrypoints/openai/api_server.py", line 230, in build_async_engine_client_from_engine_args
raise RuntimeError(
RuntimeError: Engine process failed to start. See stack trace for the root cause.
- 原因:如报错所提示,GPU 卡不支持指定的
--dtype类型(bfloat16),并指定--dtype=half的建议。 - 解决办法: 修改 vLLM 的 Deployment 中的启动参数,将
--dtype的值指定为half。
vLLM 启动报 KeyboardInterrupt: terminated 然后退出
退出前日志:
Loading safetensors checkpoint shards: 0% Completed | 0/2 [00:00<?, ?it/s]
Traceback (most recent call last):
File "/usr/local/bin/vllm", line 8, in <module>
sys.exit(main())
^^^^^^
File "/usr/local/lib/python3.12/dist-packages/vllm/scripts.py", line 204, in main
args.dispatch_function(args)
File "/usr/local/lib/python3.12/dist-packages/vllm/scripts.py", line 44, in serve
uvloop.run(run_server(args))
File "/usr/local/lib/python3.12/dist-packages/uvloop/__init__.py", line 109, in run
return __asyncio.run(
^^^^^^^^^^^^^^
File "/usr/lib/python3.12/asyncio/runners.py", line 195, in run
return runner.run(main)
^^^^^^^^^^^^^^^^
File "/usr/lib/python3.12/asyncio/runners.py", line 118, in run
return self._loop.run_until_complete(task)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "uvloop/loop.pyx", line 1512, in uvloop.loop.Loop.run_until_complete
File "uvloop/loop.pyx", line 1505, in uvloop.loop.Loop.run_until_complete
File "uvloop/loop.pyx", line 1379, in uvloop.loop.Loop.run_forever
File "uvloop/loop.pyx", line 557, in uvloop.loop.Loop._run
File "uvloop/handles/poll.pyx", line 216, in uvloop.loop.__on_uvpoll_event
File "uvloop/cbhandles.pyx", line 83, in uvloop.loop.Handle._run
File "uvloop/cbhandles.pyx", line 66, in uvloop.loop.Handle._run
File "uvloop/loop.pyx", line 399, in uvloop.loop.Loop._read_from_self
File "uvloop/loop.pyx", line 404, in uvloop.loop.Loop._invoke_signals
File "uvloop/loop.pyx", line 379, in uvloop.loop.Loop._ceval_process_signals
File "/usr/local/lib/python3.12/dist-packages/vllm/entrypoints/openai/api_server.py", line 871, in signal_handler
raise KeyboardInterrupt("terminated")
KeyboardInterrupt: terminated
- 原因: vLLM 启动慢,存活检查失败到阈值,主进程收到 SIGTERM 信号后退出。
- 解决办法: 延长
livenessProbe的initialDelaySeconds,避免因 vLLM 启动慢被终止,或者去掉livenessProbe。
vLLM 报错: max seq len is larger than the maximum number of tokens
报错日志:
ValueError: The model's max seq len (131072) is larger than the maximum number of tokens that can be stored in KV cache (93760). Try increasing `gpu_memory_utilization` or decreasing `max_model_len` when initializing the engine.
[rank0]:[W207 01:57:35.912382100 ProcessGroupNCCL.cpp:1250] Warning: WARNING: process group has NOT been destroyed before we destruct ProcessGroupNCCL. On normal program exit, the application should call destroy_process_group to ensure that any pending NCCL operations have finished in this process. In rare cases this process can exit before this point and block the progress of another member of the process group. This constraint has always been present, but this warning has only been added since PyTorch 2.4 (function operator())
Traceback (most recent call last):
File "/usr/local/bin/vllm", line 8, in <module>
sys.exit(main())
^^^^^^
File "/usr/local/lib/python3.12/dist-packages/vllm/scripts.py", line 204, in main
args.dispatch_function(args)
File "/usr/local/lib/python3.12/dist-packages/vllm/scripts.py", line 44, in serve
uvloop.run(run_server(args))
File "/usr/local/lib/python3.12/dist-packages/uvloop/__init__.py", line 109, in run
return __asyncio.run(
^^^^^^^^^^^^^^
File "/usr/lib/python3.12/asyncio/runners.py", line 195, in run
return runner.run(main)
^^^^^^^^^^^^^^^^
File "/usr/lib/python3.12/asyncio/runners.py", line 118, in run
return self._loop.run_until_complete(task)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "uvloop/loop.pyx", line 1518, in uvloop.loop.Loop.run_until_complete
File "/usr/local/lib/python3.12/dist-packages/uvloop/__init__.py", line 61, in wrapper
return await main
^^^^^^^^^^
File "/usr/local/lib/python3.12/dist-packages/vllm/entrypoints/openai/api_server.py", line 875, in run_server
async with build_async_engine_client(args) as engine_client:
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/lib/python3.12/contextlib.py", line 210, in __aenter__
return await anext(self.gen)
^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.12/dist-packages/vllm/entrypoints/openai/api_server.py", line 136, in build_async_engine_client
async with build_async_engine_client_from_engine_args(
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/lib/python3.12/contextlib.py", line 210, in __aenter__
return await anext(self.gen)
^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.12/dist-packages/vllm/entrypoints/openai/api_server.py", line 230, in build_async_engine_client_from_engine_args
raise RuntimeError(
RuntimeError: Engine process failed to start. See stack trace for the root cause.
解决办法: vllm 启动参数指定下 --max-model-len,如 --max-model-len 1024。
vLLM 或 SGLang 报错: CUDA out of memory
vLLM 报错日志:
ERROR 02-07 03:25:19 engine.py:389] CUDA out of memory. Tried to allocate 150.00 MiB. GPU 0 has a total capacity of 14.58 GiB of which 95.56 MiB is free. Process 81610 has 14.48 GiB memory in use. Of the allocated memory 14.30 GiB is allocated by PyTorch, and 34.90 MiB is reserved by PyTorch but unallocated. If reserved but unallocated memory is large try setting PYTORCH_CUDA_ALLOC_CONF=expandable_segments:True to avoid fragmentation. See documentation for Memory Management (https://pytorch.org/docs/stable/notes/cuda.html#environment-variables)
ERROR 02-07 03:25:19 engine.py:389] Traceback (most recent call last):
Process SpawnProcess-1:
ERROR 02-07 03:25:19 engine.py:389] File "/usr/local/lib/python3.12/dist-packages/vllm/engine/multiprocessing/engine.py", line 380, in run_mp_engine
ERROR 02-07 03:25:19 engine.py:389] engine = MQLLMEngine.from_engine_args(engine_args=engine_args,
ERROR 02-07 03:25:19 engine.py:389] ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
ERROR 02-07 03:25:19 engine.py:389] File "/usr/local/lib/python3.12/dist-packages/vllm/engine/multiprocessing/engine.py", line 123, in from_engine_args
ERROR 02-07 03:25:19 engine.py:389] return cls(ipc_path=ipc_path,
ERROR 02-07 03:25:19 engine.py:389] ^^^^^^^^^^^^^^^^^^^^^^
ERROR 02-07 03:25:19 engine.py:389] File "/usr/local/lib/python3.12/dist-packages/vllm/engine/multiprocessing/engine.py", line 75, in __init__
ERROR 02-07 03:25:19 engine.py:389] self.engine = LLMEngine(*args, **kwargs)
ERROR 02-07 03:25:19 engine.py:389] ^^^^^^^^^^^^^^^^^^^^^^^^^^
ERROR 02-07 03:25:19 engine.py:389] File "/usr/local/lib/python3.12/dist-packages/vllm/engine/llm_engine.py", line 276, in __init__
ERROR 02-07 03:25:19 engine.py:389] self._initialize_kv_caches()
ERROR 02-07 03:25:19 engine.py:389] File "/usr/local/lib/python3.12/dist-packages/vllm/engine/llm_engine.py", line 416, in _initialize_kv_caches
ERROR 02-07 03:25:19 engine.py:389] self.model_executor.determine_num_available_blocks())
ERROR 02-07 03:25:19 engine.py:389] ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
ERROR 02-07 03:25:19 engine.py:389] File "/usr/local/lib/python3.12/dist-packages/vllm/executor/executor_base.py", line 101, in determine_num_available_blocks
ERROR 02-07 03:25:19 engine.py:389] results = self.collective_rpc("determine_num_available_blocks")
ERROR 02-07 03:25:19 engine.py:389] ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
ERROR 02-07 03:25:19 engine.py:389] File "/usr/local/lib/python3.12/dist-packages/vllm/executor/uniproc_executor.py", line 51, in collective_rpc
ERROR 02-07 03:25:19 engine.py:389] answer = run_method(self.driver_worker, method, args, kwargs)
ERROR 02-07 03:25:19 engine.py:389] ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
ERROR 02-07 03:25:19 engine.py:389] File "/usr/local/lib/python3.12/dist-packages/vllm/utils.py", line 2220, in run_method
ERROR 02-07 03:25:19 engine.py:389] return func(*args, **kwargs)
ERROR 02-07 03:25:19 engine.py:389] ^^^^^^^^^^^^^^^^^^^^^
ERROR 02-07 03:25:19 engine.py:389] File "/usr/local/lib/python3.12/dist-packages/torch/utils/_contextlib.py", line 116, in decorate_context
ERROR 02-07 03:25:19 engine.py:389] return func(*args, **kwargs)
ERROR 02-07 03:25:19 engine.py:389] ^^^^^^^^^^^^^^^^^^^^^
ERROR 02-07 03:25:19 engine.py:389] File "/usr/local/lib/python3.12/dist-packages/vllm/worker/worker.py", line 229, in determine_num_available_blocks
ERROR 02-07 03:25:19 engine.py:389] self.model_runner.profile_run()
ERROR 02-07 03:25:19 engine.py:389] File "/usr/local/lib/python3.12/dist-packages/torch/utils/_contextlib.py", line 116, in decorate_context
ERROR 02-07 03:25:19 engine.py:389] return func(*args, **kwargs)
ERROR 02-07 03:25:19 engine.py:389] ^^^^^^^^^^^^^^^^^^^^^
ERROR 02-07 03:25:19 engine.py:389] File "/usr/local/lib/python3.12/dist-packages/vllm/worker/model_runner.py", line 1235, in profile_run
ERROR 02-07 03:25:19 engine.py:389] self._dummy_run(max_num_batched_tokens, max_num_seqs)
ERROR 02-07 03:25:19 engine.py:389] File "/usr/local/lib/python3.12/dist-packages/vllm/worker/model_runner.py", line 1346, in _dummy_run
ERROR 02-07 03:25:19 engine.py:389] self.execute_model(model_input, kv_caches, intermediate_tensors)
ERROR 02-07 03:25:19 engine.py:389] File "/usr/local/lib/python3.12/dist-packages/torch/utils/_contextlib.py", line 116, in decorate_context
ERROR 02-07 03:25:19 engine.py:389] return func(*args, **kwargs)
ERROR 02-07 03:25:19 engine.py:389] ^^^^^^^^^^^^^^^^^^^^^
ERROR 02-07 03:25:19 engine.py:389] File "/usr/local/lib/python3.12/dist-packages/vllm/worker/model_runner.py", line 1775, in execute_model
ERROR 02-07 03:25:19 engine.py:389] output: SamplerOutput = self.model.sample(
ERROR 02-07 03:25:19 engine.py:389] ^^^^^^^^^^^^^^^^^^
ERROR 02-07 03:25:19 engine.py:389] File "/usr/local/lib/python3.12/dist-packages/vllm/model_executor/models/qwen2.py", line 505, in sample
ERROR 02-07 03:25:19 engine.py:389] next_tokens = self.sampler(logits, sampling_metadata)
ERROR 02-07 03:25:19 engine.py:389] ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
ERROR 02-07 03:25:19 engine.py:389] File "/usr/local/lib/python3.12/dist-packages/torch/nn/modules/module.py", line 1736, in _wrapped_call_impl
ERROR 02-07 03:25:19 engine.py:389] return self._call_impl(*args, **kwargs)
ERROR 02-07 03:25:19 engine.py:389] ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
ERROR 02-07 03:25:19 engine.py:389] File "/usr/local/lib/python3.12/dist-packages/torch/nn/modules/module.py", line 1747, in _call_impl
ERROR 02-07 03:25:19 engine.py:389] return forward_call(*args, **kwargs)
ERROR 02-07 03:25:19 engine.py:389] ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
ERROR 02-07 03:25:19 engine.py:389] File "/usr/local/lib/python3.12/dist-packages/vllm/model_executor/layers/sampler.py", line 271, in forward
SGLang 报错日志:
torch.OutOfMemoryError: CUDA out of memory. Tried to allocate 540.00 MiB. GPU 0 has a total capacity of 14.76 GiB of which 298.75 MiB is free. Process 63729 has 14.46 GiB memory in use. Of the allocated memory 14.35 GiB is allocated by PyTorch, and 1.52 MiB is reserved by PyTorch but unallocated. If reserved but unallocated memory is large try setting PYTORCH_CUDA_ALLOC_CONF=expandable_segments:True to avoid fragmentation. See documentation for Memory Management (https://pytorch.org/docs/stable/notes/cuda.html#environment-variables)
- 原因: GPU 卡显存不够。
- 解决方案: 换显存更大的 GPU 卡,或使用多机部署组成 GPU 集群。
SGLang 报错:SGLang only supports sm75 and above.
报错日志:
[2025-02-12 02:56:48 TP0] Compute capability below sm80. Use float16 due to lack of bfloat16 support.
[2025-02-12 02:56:48 TP0] Scheduler hit an exception: Traceback (most recent call last):
File "/sgl-workspace/sglang/python/sglang/srt/managers/scheduler.py", line 1787, in run_scheduler_process
scheduler = Scheduler(server_args, port_args, gpu_id, tp_rank, dp_rank)
File "/sgl-workspace/sglang/python/sglang/srt/managers/scheduler.py", line 240, in __init__
self.tp_worker = TpWorkerClass(
File "/sgl-workspace/sglang/python/sglang/srt/managers/tp_worker_overlap_thread.py", line 63, in __init__
self.worker = TpModelWorker(server_args, gpu_id, tp_rank, dp_rank, nccl_port)
File "/sgl-workspace/sglang/python/sglang/srt/managers/tp_worker.py", line 68, in __init__
self.model_runner = ModelRunner(
File "/sgl-workspace/sglang/python/sglang/srt/model_executor/model_runner.py", line 186, in __init__
self.load_model()
File "/sgl-workspace/sglang/python/sglang/srt/model_executor/model_runner.py", line 293, in load_model
raise RuntimeError("SGLang only supports sm75 and above.")
RuntimeError: SGLang only supports sm75 and above.
- 原因:GPU 显卡计算能力不够,提示至少计算能力要 SM7.5
- 解决方案:换成计算能力大于等于 SM7.5 的 GPU,如 T4、A100
GPU 数量需被注意力头数整除
在进行多机部署时,需确保模型的注意力头数能整除总 GPU 数量,否则加载模型就会报错:
- vLLM 报错
- SGLang 报错
ValueError: Total number of attention heads (32) must be divisible by tensor parallel size
[2025-02-14 02:47:45 TP0] Scheduler hit an exception: Traceback (most recent call last):
File "/sgl-workspace/sglang/python/sglang/srt/managers/scheduler.py", line 1816, in run_scheduler_process
scheduler = Scheduler(server_args, port_args, gpu_id, tp_rank, dp_rank)
File "/sgl-workspace/sglang/python/sglang/srt/managers/scheduler.py", line 240, in __init__
self.tp_worker = TpWorkerClass(
File "/sgl-workspace/sglang/python/sglang/srt/managers/tp_worker_overlap_thread.py", line 63, in __init__
self.worker = TpModelWorker(server_args, gpu_id, tp_rank, dp_rank, nccl_port)
File "/sgl-workspace/sglang/python/sglang/srt/managers/tp_worker.py", line 68, in __init__
self.model_runner = ModelRunner(
File "/sgl-workspace/sglang/python/sglang/srt/model_executor/model_runner.py", line 194, in __init__
self.load_model()
File "/sgl-workspace/sglang/python/sglang/srt/model_executor/model_runner.py", line 317, in load_model
self.model = get_model(
File "/sgl-workspace/sglang/python/sglang/srt/model_loader/__init__.py", line 22, in get_model
return loader.load_model(
File "/sgl-workspace/sglang/python/sglang/srt/model_loader/loader.py", line 357, in load_model
model = _initialize_model(
File "/sgl-workspace/sglang/python/sglang/srt/model_loader/loader.py", line 138, in _initialize_model
return model_class(
File "/sgl-workspace/sglang/python/sglang/srt/models/qwen2.py", line 332, in __init__
self.model = Qwen2Model(config, quant_config=quant_config)
File "/sgl-workspace/sglang/python/sglang/srt/models/qwen2.py", line 241, in __init__
self.layers = make_layers(
File "/sgl-workspace/sglang/python/sglang/srt/utils.py", line 313, in make_layers
[
File "/sgl-workspace/sglang/python/sglang/srt/utils.py", line 314, in <listcomp>
maybe_offload_to_cpu(layer_fn(idx=idx, prefix=f"{prefix}.{idx}"))
File "/sgl-workspace/sglang/python/sglang/srt/models/qwen2.py", line 243, in <lambda>
lambda idx, prefix: Qwen2DecoderLayer(
File "/sgl-workspace/sglang/python/sglang/srt/models/qwen2.py", line 180, in __init__
self.self_attn = Qwen2Attention(
File "/sgl-workspace/sglang/python/sglang/srt/models/qwen2.py", line 105, in __init__
assert self.total_num_heads % tp_size == 0
AssertionError
模型的注意力头数等于模型文件 config.json 中 num_attention_heads 的值,比如 DeepSeek-R1-Distill-Qwen-32B 的注意力头数为 40:
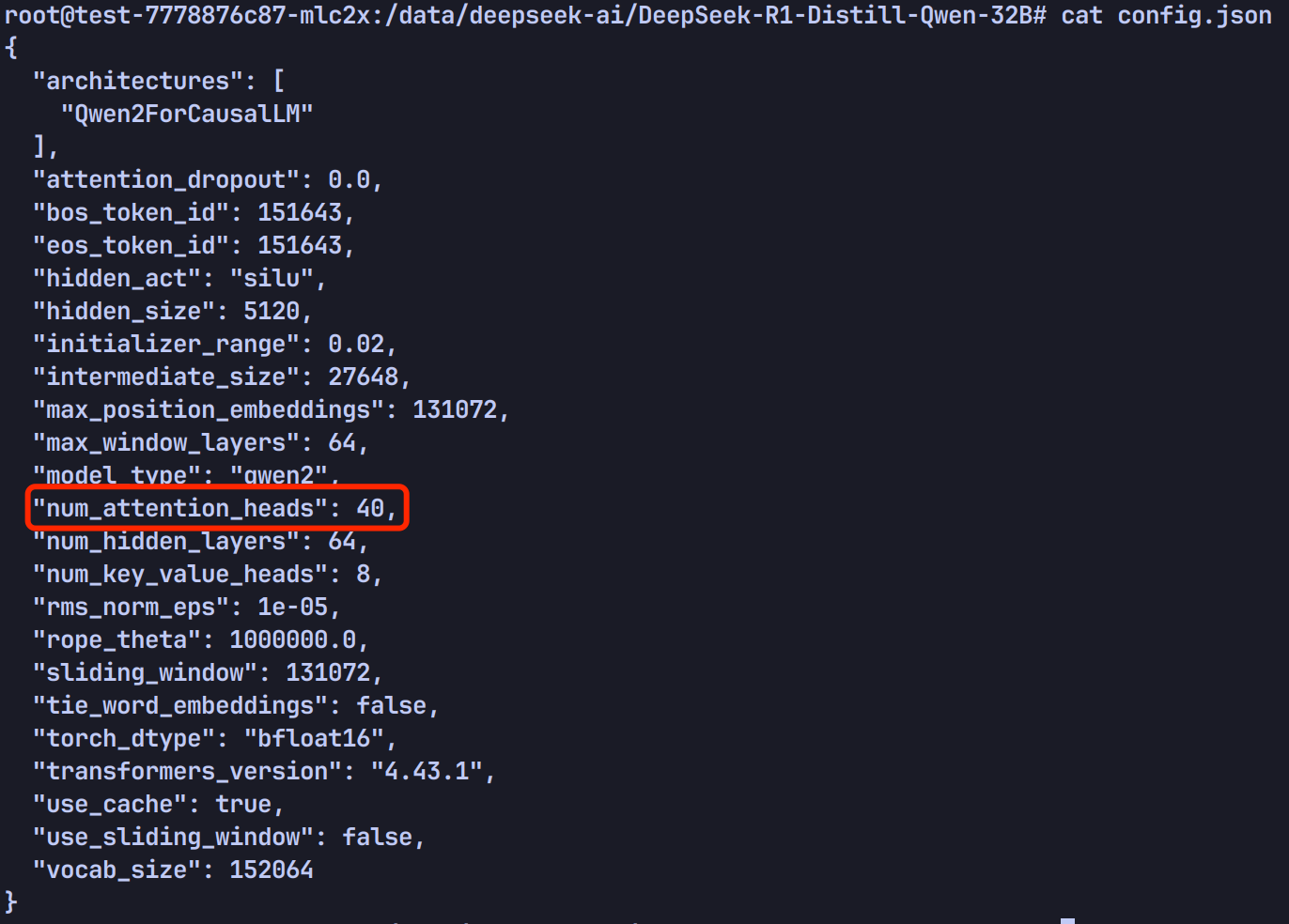
如果每台节点一张 GPU 卡,总共 3 个节点,那么 40 / 3 无法整除,启动就会报错,改成 2 台节点反而可以成功(40 / 2 可以整除)。