Serverless 弹性集群注意事项
访问公网
与 TKE 集群不同的是,EKS 没有节点,无法像 TKE 那样,Pod 可以利用节点自身的公网带宽访问公网。
EKS 没有节点,要让 Pod 访问公网有两种方式:
大多情况下可以考虑方式一,创建 NAT 网关,在 VPC 路由表里配置路由,如果希望整个 VPC 都默认走这个 NAT 网关出公网,可以修改 default 路由表:

如果只想让超级节点的 Pod 走这个 NAT 网关,可以新建路由表。
配置方法是在路由表新建一条路由策略,0.0.0.0/0 网段的下一条类型为 NAT 网关,且选择前面创建的 NAT 网关实例:
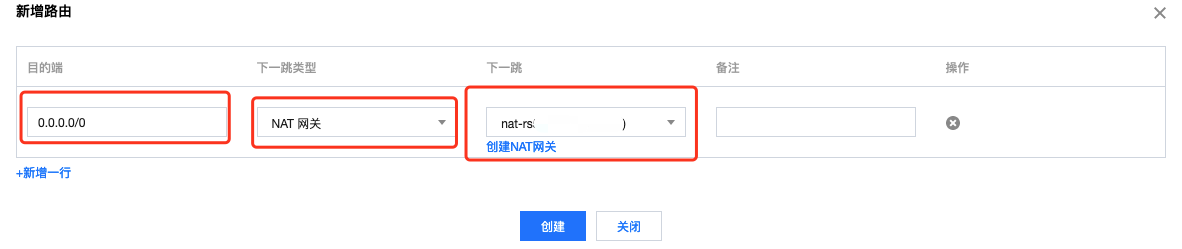
创建好后,如果不是 default 路由表,需要关联一下超级节点的子网:

9100 端口
EKS 默认会在每个 Pod 的 9100 端口进行监听,暴露 Pod 相关监控指标,如果业务本身也监听 9100,会失败,参考 9100 端口问题。
注意配额限制
使用 EKS 集群时注意一下配额限制,如果不够,可以提工单调高上限:
- 单集群 Pod 数量上限 (默认200)。
- 安全组绑定实例数量上限 (如果不给 Pod 指定安全组,会使用当前项目当前地域的默认安全组,每个安全组绑定实例数量上限为 2000)。
ipvs 超时时间问题
istio 场景 dns 超时
istio 的 sidecar (istio-proxy) 拦截流量借助了 conntrack 来实现连接跟踪,当部分没有拦截的流量 (比如 UDP) 通过 service 访问时,会经过 ipvs 转发,而 ipvs 和 conntrack 对连接都有一个超时时间设置,如果在 ipvs 和 conntrack 中的超时时间不一致,就可能出现 conntrack 中连接还在,但在 ipvs 中已被清理而导致出去的包被 ipvs 调度到新的 rs,而 rs 回包的时候匹配不到 conntrack,不会做反向 SNAT,从而导致进程收不到回包。
在 EKS 中,ipvs 超时时间当前默认是 5s,而 conntrack 超时时间默认是 120s,如果在 EKS 中使用 TCM 或自行安装 istio,当 coredns 扩容后一段时间,业务解析域名时就可能出现 DNS 超时。
在产品化解决之前,我们可以给 Pod 加如下注解,将 ipvs 超时时间也设成 120s,与 conntrack 超时时间对齐:
eks.tke.cloud.tencent.com/ipvs-udp-timeout: "120s"
gRPC 场景 Connection reset by peer
gRPC 是长连接,Java 版的 gRPC 默认 idle timeout 是 30 分钟,并且没配置 TCP 连接的 keepalive 心跳,而 ipvs 默认的 tcp timeout 是 15 分钟。
这就会导致一个问题: 业务闲置 15 分钟后,ipvs 断开连接,但是上层应用还认为连接在,还会复用连接发包,而 ipvs 中对应连接已不存在,会直接响应 RST 来将连接断掉,从业务日志来看就是 Connection reset by peer。
这种情况,如果不想改代码来启用 keepalive,可以直接调整下 eks 的 ipvs 的 tcp timeout 时间,与业务 idle timeout 时长保持一致:
eks.tke.cloud.tencent.com/ipvs-tcp-timeout: "1800s"