CLB Loopback Issues
Problem Description
Some TKE users may encounter service connectivity issues or several seconds of delay when accessing Ingress due to CLB loopback problems. This article introduces the background, causes, and provides some considerations and recommendations.
What are the Symptoms?
CLB loopback may cause the following symptoms:
- Whether using iptables or ipvs mode, accessing internal Ingress within the same cluster results in 4-second delays or complete connectivity failure.
- In ipvs mode, accessing internal LoadBalancer type Service within the cluster shows complete connectivity failure or intermittent connectivity.
Why Does Loopback Occur?
The fundamental reason is that when CLB forwards requests to backend servers (rs), both the source and destination IP addresses of the packets are within the same node, causing data packets to loop back internally within the machine:
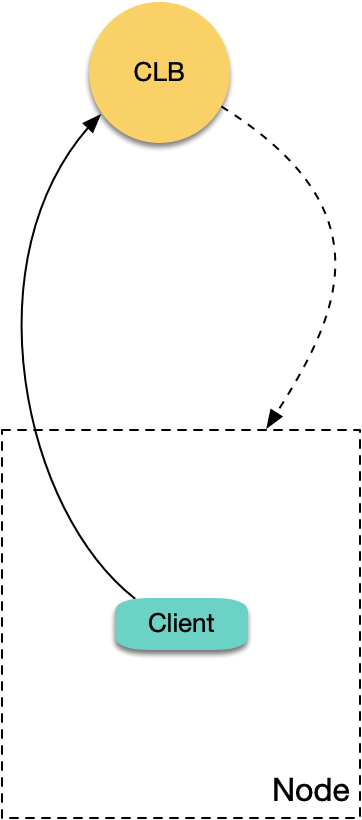
Let's analyze specific scenarios below.
Analyzing Ingress Loopback
First, let's analyze Ingress. Using TKE's default Ingress creates a CLB for each Ingress resource with 80/443 layer 7 listener rules (HTTP/HTTPS), and binds each location to the same NodePort across TKE nodes as backend servers (each location corresponds to a Service, and each Service exposes traffic through the same NodePort on each node). CLB matches requests to locations and forwards them to the corresponding NodePorts. Traffic reaching NodePort is then forwarded by K8S iptables or ipvs to the corresponding backend pods. When pods in the cluster access internal Ingress within the same cluster, CLB forwards requests to the corresponding NodePort on one of the nodes:
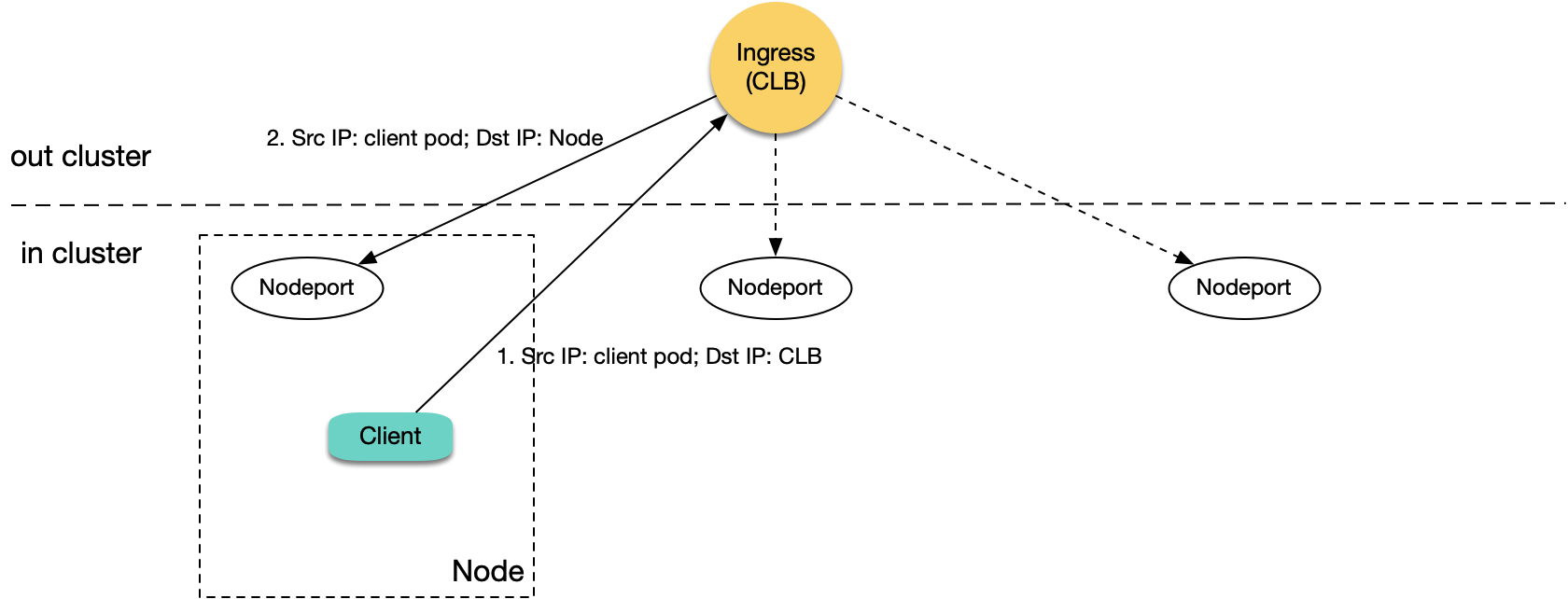
As shown in the diagram, when the forwarding node happens to be the same node where the client request originates:
- Pods in the cluster access CLB, which then forwards requests to the corresponding NodePort on any node.
- When packets reach NodePort, the destination IP is the node IP, and the source IP is the real IP of the client pod, because CLB doesn't perform SNAT and passes through the real source IP.
- Since both source and destination IPs are within the same machine, loopback occurs, and CLB won't receive responses from the backend servers.
Why do failures when accessing cluster-internal Ingress mostly show as several seconds of delay? Because layer 7 CLB will retry the next backend server if the request times out (approximately 4 seconds). So if the client side has a longer timeout setting, the loopback problem manifests as slow request response with several seconds of delay. Of course, if the cluster has only one node, CLB has no other backend servers to retry, and the symptom is complete connectivity failure.
Analyzing LoadBalancer Service Loopback
Having analyzed the layer 7 CLB scenario, let's examine layer 4 CLB. When using internal LoadBalancer type Services to expose services, an internal CLB is created with corresponding layer 4 listeners (TCP/UDP). When pods in the cluster access the EXTERNAL-IP of LoadBalancer type Services (i.e., CLB IP), native K8S doesn't actually access the LB but directly forwards to backend pods through iptables or ipvs (without going through CLB):
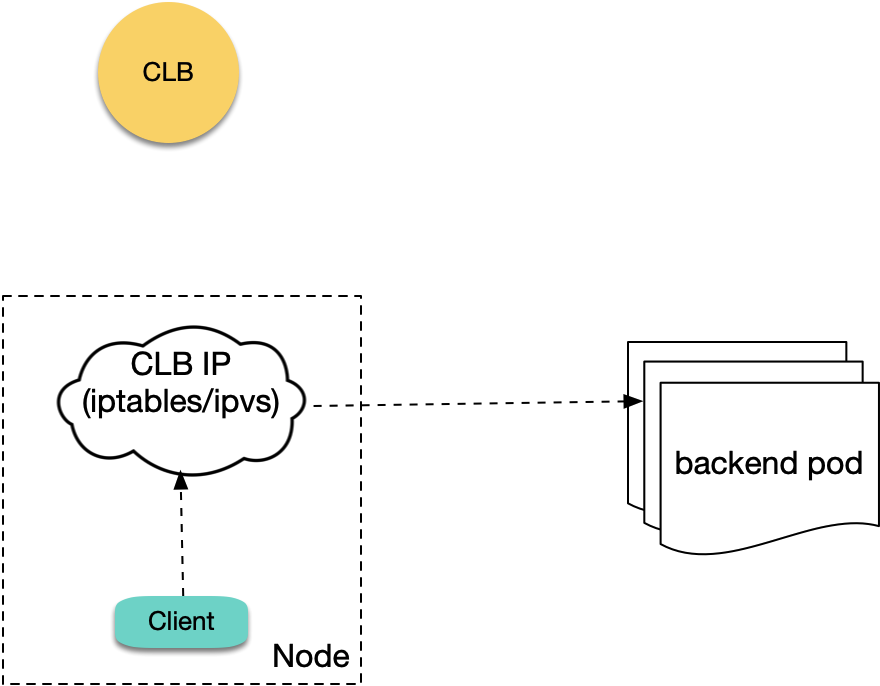
So native K8S logic doesn't have this problem. However, in TKE's ipvs mode, packets from clients accessing CLB IP actually reach CLB, so when pods in ipvs mode access CLB IP of LoadBalancer type Services within the same cluster, they encounter loopback issues similar to internal Ingress loopback:
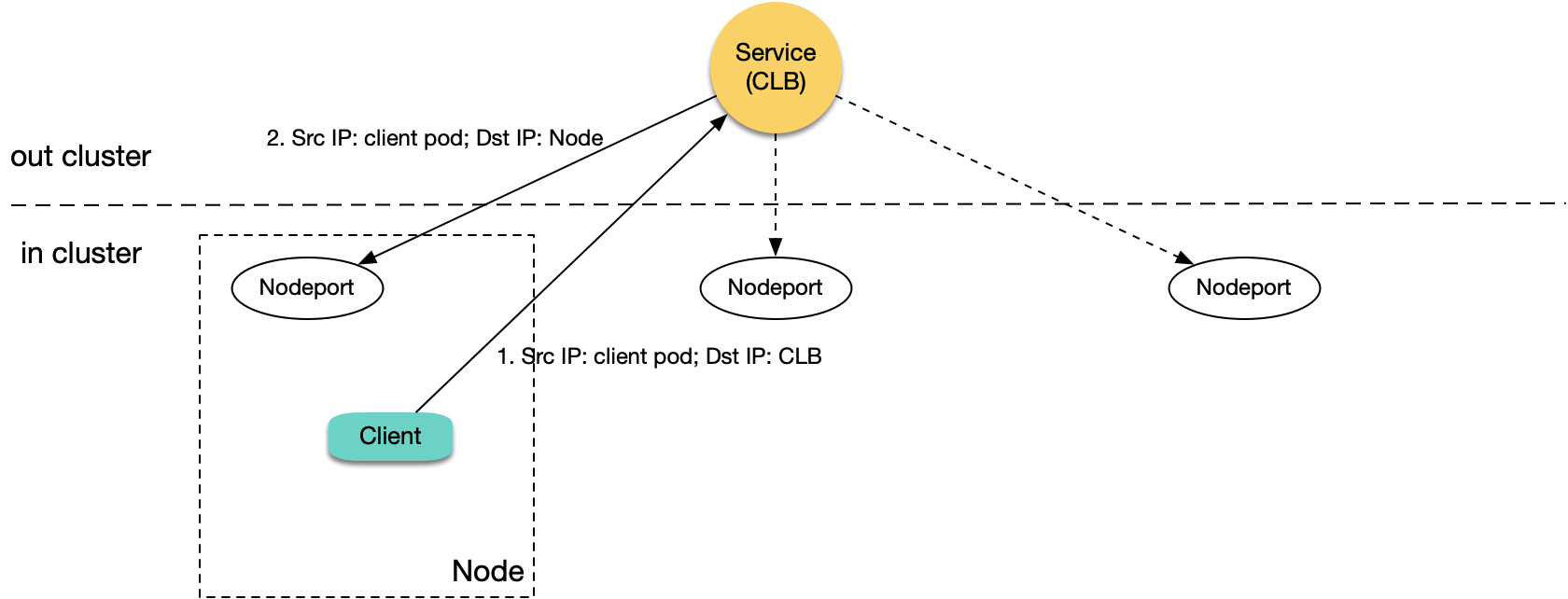
One difference is that layer 4 CLB doesn't retry the next backend server. When encountering loopback, the symptom is usually intermittent connectivity; of course, if the cluster has only one node, it's complete connectivity failure.
Why doesn't TKE's ipvs mode use native K8S forwarding logic (bypassing LB, directly forwarding to backend pods)? This goes back to an issue I discovered in July 2019 that hasn't been resolved by the community yet: https://github.com/kubernetes/kubernetes/issues/79783
Here's some background: Previously, TKE ipvs mode clusters using LoadBalancer internal Services had all health probes from internal CLB to backend NodePorts fail. The reasons were:
- ipvs mainly works on the INPUT chain and needs to treat VIPs (Service Cluster IP and
EXTERNAL-IP) as local IPs to allow packets to enter the INPUT chain for ipvs processing. - kube-proxy's approach was to bind both Cluster IP and
EXTERNAL-IPto a dummy network interface calledkube-ipvs0, which is only used for binding VIPs (kernel automatically generates local routes for it) and not for receiving traffic. - Health probe packets from internal CLB to NodePorts have source IP as CLB's own VIP and destination IP as Node IP. When probe packets reach the node, the node recognizes the source IP as its own IP (since it's bound to
kube-ipvs0) and discards it. So CLB probe packets never receive responses, resulting in all probe failures. Although CLB has all-or-nothing logic (all probe failures are considered as all being forwardable), this essentially makes the probes ineffective and can cause anomalies in certain situations.
To solve this problem, TKE's fix strategy was: ipvs mode doesn't bind EXTERNAL-IP to kube-ipvs0. This means that packets from pods accessing CLB IP within the cluster won't enter the INPUT chain but will exit the node's network interface directly, actually reaching CLB. This way, health probe packets entering the node won't be treated as local IPs and discarded, and probe response packets won't enter the INPUT chain and get stuck.
Although this method fixes the CLB health probe failure issue, it also causes packets from pods accessing CLB within the cluster to actually reach CLB. Since they're accessing services within the cluster, packets get forwarded back to one of the nodes, creating the possibility of loopback.
Why Don't Public CLBs Have This Problem?
Using public Ingress and LoadBalancer type public Services doesn't have loopback issues. My understanding is mainly because public CLBs receive packets with source IPs being the machine's egress public IP, and the machine internally doesn't recognize its own public IP. When packets are forwarded back to the machine, it doesn't consider the public source IP as its own IP, thus avoiding loopback.
Does CLB Have Loopback Prevention Mechanisms?
Yes. CLB checks the source IP and if it finds that the backend server has the same IP, it won't consider forwarding to that backend server and will choose another one. However, the source Pod IP and backend server IP are different, and CLB doesn't know these two IPs are on the same node, so it might still forward there, potentially causing loopback.
Can Anti-Affinity Deployment Between Client and Server Avoid This?
If I deploy client and server with anti-affinity to avoid them being scheduled on the same node, can this avoid the problem? By default, LB binds backend servers through node NodePorts and may forward to any node's NodePort. In this case, loopback may occur regardless of whether client and server are on the same node. However, if you set externalTrafficPolicy: Local for the Service, LB will only forward to nodes with server pods. If client and server are scheduled on different nodes through anti-affinity, loopback won't occur. So anti-affinity + externalTrafficPolicy: Local can avoid this problem (including internal Ingress and LoadBalancer type internal Services), though it's a bit cumbersome.
Does LB Direct-to-Pod in VPC-CNI Also Have This Problem?
TKE typically uses Global Router network mode (bridge solution), and there's also VPC-CNI (elastic network interface solution). Currently, LB direct-to-pod only supports VPC-CNI pods, meaning LB doesn't bind NodePorts as backend servers but directly binds backend pods as backend servers:
This bypasses NodePort and avoids forwarding to any random node. However, if client and server are on the same node, loopback may still occur and can be avoided through anti-affinity.
What Are the Recommendations?
Anti-affinity and externalTrafficPolicy: Local avoidance methods are not very elegant. Generally, when accessing services within the cluster, avoid accessing the cluster's CLB. Since the service itself is within the cluster, going through CLB not only increases network path length but also causes loopback issues.
When accessing services within the cluster, try to use Service names, such as: server.prod.svc.cluster.local. This bypasses CLB and avoids loopback problems.
If the business has coupled domain names and cannot use Service names, you can use CoreDNS's rewrite plugin to point domain names to services within the cluster. CoreDNS configuration example:
apiVersion: v1
kind: ConfigMap
metadata:
name: coredns
namespace: kube-system
data:
Corefile: |2-
.:53 {
rewrite name roc.oa.com server.prod.svc.cluster.local
...
If multiple Services share the same domain name, you can deploy your own Ingress Controller (like nginx-ingress), use the rewrite method above to point the domain name to your own Ingress Controller, and then have your own Ingress match Services based on request location (domain + path) and forward to backend pods. This entire path also bypasses CLB and can avoid loopback problems.
Summary
This article provides a detailed overview of TKE's CLB loopback issues, explaining their causes and providing some avoidance recommendations.