Kubernetes 网络疑难杂症排查分享
大家好,我是 roc,来自腾讯云容器服务(TKE)团队,经常帮助用户解决各种 K8S 的疑难杂症,积累了比较丰富的经验,本文分享几个比较复杂的网络方面的问题排查和解决思路,深入分析并展开相关知识,信息量巨大,相关经验不足的同学可能需要细细品味才能消化,我建议收藏本文反复研读,当完全看懂后我相信你的功底会更加扎实,解决问题的能力会大大提升。
本文发现的问题是在使用 TKE 时遇到的,不同厂商的网络环境可能不一样�,文中会对不同的问题的网络环境进行说明

跨 VPC 访问 NodePort 经常超时
现象: 从 VPC a 访问 VPC b 的 TKE 集群的某个节点的 NodePort,有时候正常,有时候会卡住直到超时。
原因怎么查?

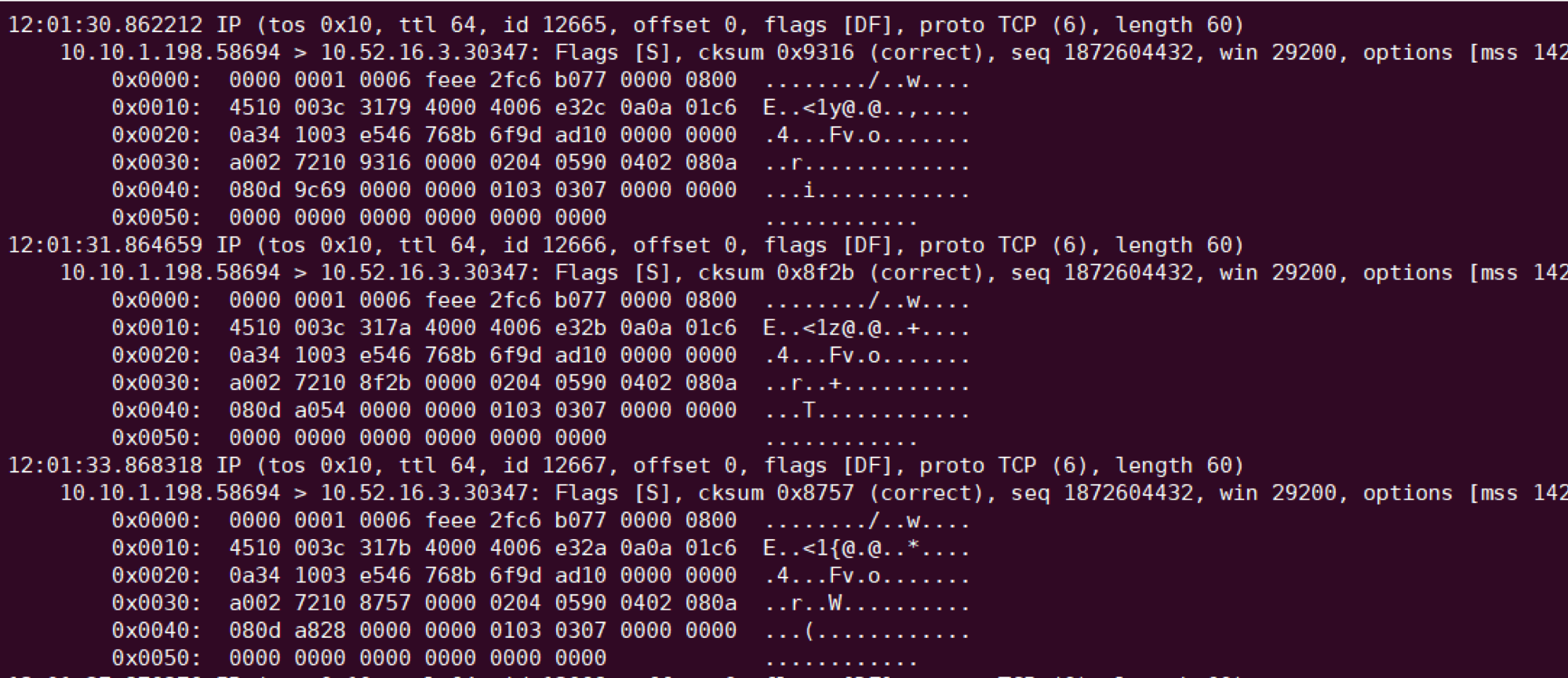
当然是先抓包看看啦,抓 server 端 NodePort 的包,发现异常时 server 能收到 SYN,但没响应 ACK:
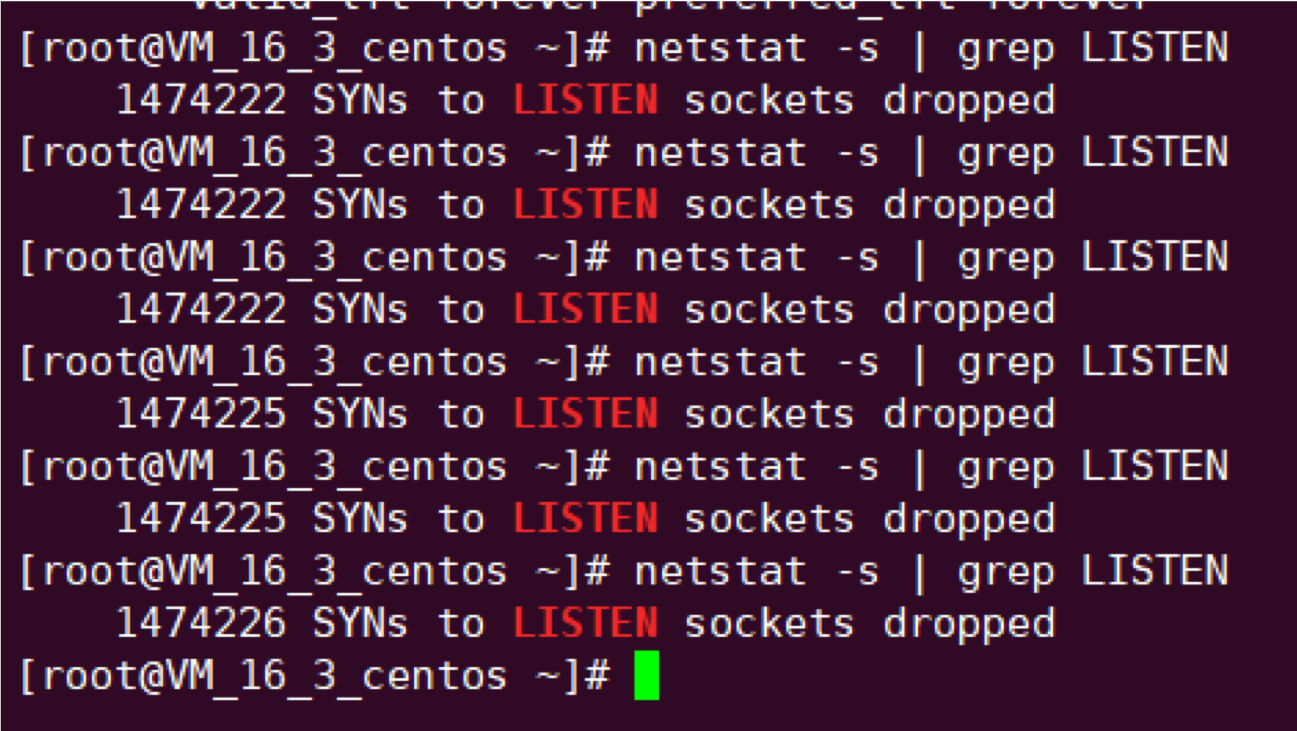
反复执行 netstat -s | grep LISTEN 发现 SYN 被丢弃数量不断增加:
分析:
- 两个VPC之间使用对等连接打通的,CVM 之间通信应该就跟在一个内网一样可以互通。
- 为什么同一 VPC 下访问没问题,跨 VPC 有问题? 两者访问的区别是什么?

再仔细看下 client 所在环境,发现 client 是 VPC a 的 TKE 集群节点,捋一下:
- client 在 VPC a 的 TKE 集群的节点
- server 在 VPC b 的 TKE 集群的节点
因为 TKE 集群中有个叫 ip-masq-agent 的 daemonset,它会给 node 写 iptables 规则,默认 SNAT 目的 IP 是 VPC 之外的报文,所以 client 访问 server 会做 SNAT,也就是这里跨 VPC 相比同 VPC 访问 NodePort 多了一次 SNAT,如果是因为多了一次 SNAT 导致的这个问题,直觉告诉我这个应该跟内核参数有关,因为是 server 收到包没回包,所以应该是 server 所在 node 的内核参数问题,对比这个 node 和 普通 TKE node 的默认内核参数,发现这个 node net.ipv4.tcp_tw_recycle = 1,这个参数默认是关闭的,跟用户沟通后发现这个内核参数确实在做压测的时候调整过。

解释一下,TCP 主动关闭连接的一方在发送最后一个 ACK 会进入 TIME_AWAIT 状态,再等待 2 个 MSL 时间后才会关闭(因为如果 server 没收到 client 第四次挥手确认报文,server 会重发第三次挥手 FIN 报文,所以 client 需要停留 2 MSL的时长来处理可能会重复收到的报文段;同时等待 2 MSL 也可以让由于网络不通畅产生的滞留报文失效,避免新建立的连接收到之前旧连接的报文),了解更详细的过程请参考 TCP 四次挥手。
参数 tcp_tw_recycle 用于快速回收 TIME_AWAIT 连接,通常在增加连接并发能力的场景会开启,比如发起大量短连接,快速回收可避免 tw_buckets 资源耗尽导致无法建立新连接 (time wait bucket table overflow)
查得 tcp_tw_recycle 有个坑,在 RFC1323 有段描述:
An additional mechanism could be added to the TCP, a per-host cache of the last timestamp received from any connection. This value could then be used in the PAWS mechanism to reject old duplicate segments from earlier incarnations of the connection, if the timestamp clock can be guaranteed to have ticked at least once since the old connection was open. This would require that the TIME-WAIT delay plus the RTT together must be at least one tick of the sender’s timestamp clock. Such an extension is not part of the proposal of this RFC.
大概意思是说 TCP 有一种行为,可以缓存每个连接最新的时间戳,后续请求中如果时间戳小于缓存的时间戳,即视为无效,相应的数据包会被丢弃。
Linux 是否启用这种行为取决于 tcp_timestamps 和 tcp_tw_recycle,因为 tcp_timestamps 缺省开启,所以当 tcp_tw_recycle 被开启后,实际上这种行为就被激活了,当客户端或服务端以 NAT 方式构建的时候就可能出现问题。
当多个客户端通过 NAT 方式联网并与服务端交互时,服务端看到的是同一个 IP,也就是说对服务端而言这些客户端实际上等同于一个,可惜由于这些客户端的时间戳可能存在差异,于是乎从服务端的视角看,便可能出现时间戳错乱的现象,进而直接导致时间戳小的数据包被丢弃。如果发生了此类问题,具体的表现通常是是客户端明明发送的 SYN,但服务端就是不响应 ACK。
回到我们的问题上,client 所在节点上可能也会有其它 pod 访问到 server 所在节点,而它们都被 SNAT 成了 client 所在节点的 NODE IP,但时间戳存在差异,server 就会看到时间戳错乱,因为开启了 tcp_tw_recycle 和 tcp_timestamps 激活了上述行为,就丢掉了比缓存时间戳小的报文,导致部分 SYN 被丢弃,这也解释了为什么之前我们抓包发现异常时 server 收到了 SYN,但没有响应 ACK,进而说明为什么 client 的请求部分会卡住直到超时。
由于 tcp_tw_recycle 坑太多,在内核 4.12 之后已移除: remove tcp_tw_recycle

LB 压测 CPS 低
现象: LoadBalancer 类型的 Service,直接压测 NodePort CPS 比较高,但如果压测 LB CPS 就很低。
环境说明: 用户使用的黑石TKE,不是公有云TKE,黑石的机器是物理机,LB的实现也跟公有云不一样,但 LoadBalancer 类型的 Service 的实现同样也是 LB 绑定各节点的 NodePort,报文发到 LB 后转到节点的 NodePort, 然后再路由到对应 pod,而测试在公有云 TKE 环境下没有这个问题。
client 抓包: 大量SYN重传。
server 抓包: 抓 NodePort 的包,发现当 client SYN 重传时 server 能收到 SYN 包但没有响应。
又是 SYN 收到但没响应,难道又是开启 tcp_tw_recycle 导致的?检查节点的内核参数发现并没有开启,除了这个原因,还会有什么情况能导致被丢弃?
conntrack -S 看到 insert_failed 数量在不断增加,也就是 conntrack 在插入很多新连接的时候失败了,为什么会插入失败?什么情况下会插入失败?

挖内核源码: netfilter conntrack 模块为每个连接创建 conntrack 表项时,表项的创建和最终插入之间还有一段逻辑,没有加锁,是一种乐观锁的过程。conntrack 表项并发刚创建时五元组不冲突的话可以创建成功,但中间经过 NAT 转换之后五元组就可能变成相同,第一个可以插入成功,后面的就会插入失败,因为已经有相同的表项存在。比如一个 SYN 已经做了 NAT 但是还没到最终插入的时候,另一个 SYN 也在做 NAT,因为之前那个 SYN 还没插入,这个 SYN 做 NAT 的时候就认为这个五元组没有被占用,那么它 NAT 之后的五元组就可能跟那个还没插入的包相同。
在我们这个问题里实际就是 netfilter 做 SNAT 时源端口选举冲突了,黑石 LB 会做 SNAT,SNAT 时使用了 16 个不同 IP 做源,但是短时间内源 Port 却是集中一致的,并发两个 SYN a 和SYN b,被 LB SNAT 后源 IP 不同但源 Port 很可能相同,这里就假设两个报文被 LB SNAT 之后它们源 IP 不同源 Port 相同,报文同时到了节点的 NodePort 会再次做 SNAT 再转发到对应的 Pod,当报文到了 NodePort 时,这时它们五元组不冲突,netfilter 为它们分别创建了 conntrack 表项,SYN a 被节点 SNAT 时默认行为是 从 port_range 范围的当前源 Port 作为起始位置开始循环遍历,选举出没有被占用的作为源 Port,因为这两个 SYN 源 Port 相同,所以它们源 Port 选举的起始位置相同,当 SYN a 选出源 Port 但还没将 conntrack 表项插入时,netfilter 认为这个 Port 没被占用就很可能给 SYN b 也选了相同的源 Port,这时他们五元组就相同了,当 SYN a 的 conntrack 表项插入后再插入 SYN b 的 conntrack 表项时,发现已经有相同的记录就将 SYN b 的 conntrack 表项丢弃了。
解决方法探索: 不使用源端口选举,在 iptables 的 MASQUERADE 规则如果加 --random-fully 这个 flag �可以让端口选举完全随机,基本上能避免绝大多数的冲突,但也无法完全杜绝。最终决定开发 LB 直接绑 Pod IP,不基于 NodePort,从而避免 netfilter 的 SNAT 源端口冲突问题。

DNS 解析偶尔 5S 延时
网上一搜,是已知问题,仔细分析,实际跟之前黑石 TKE 压测 LB CPS 低的根因是同一个,都是因为 netfilter conntrack 模块的设计问题,只不过之前发生在 SNAT,这个发生在 DNAT,这里用我的语言来总结下原因:
DNS client (glibc 或 musl libc) 会并发请求 A 和 AAAA 记录,跟 DNS Server 通信自然会先 connect (建立fd),后面请求报文使用这个 fd 来发送,由于 UDP 是无状态协议, connect 时并不会发包,也就不会创建 conntrack 表项, 而并发请求的 A 和 AAAA 记录默认使用同一个 fd 发包,send 时各自发的包它们源 Port 相同(因为用的同一个socket发送),当并发发包时,两个包都还没有被插入 conntrack 表项,所以 netfilter 会为它们分别创建 conntrack 表项,而集群内请求 kube-dns 或 coredns 都是访问的CLUSTER-IP,报文最终会被 DNAT 成一个 endpoint 的 POD IP,当两个包恰好又被 DNAT 成同一个 POD IP时,它们的五元组就相同了,在最终插入的时候后面那个包就会被丢掉,如果 dns 的 pod 副本只有一个实例的情况就很容易发生(始终被DNAT成同一个POD IP),现象就是 dns 请求超时,client 默认策略是等待 5s 自动重试,如果重试成功,我们看到的现象就是 dns 请求有 5s 的延时。
参考 weave works 工程师总结的文章: Racy conntrack and DNS lookup timeouts
解决方案一: 使用 TCP 发送 DNS 请求
如果使用 TCP 发 DNS 请求,connect 时就会发包建立连接并插入 conntrack 表项,而后并发的 A 和 AAAA 记录的请求在 send 时都使用 connect 建立好的这个 fd,由于 connect 时 conntrack 表项已经建立,所以 send 时不会再建立,也就不存在并发创建 conntrack 表项,避免了冲突。
resolv.conf 可以加 options use-vc 强制 glibc 使用 TCP 协议发送 DNS query。下面是这个 man resolv.conf中关于这个选项的说明:
use-vc (since glibc 2.14)
Sets RES_USEVC in _res.options. This option forces the
use of TCP for DNS resolutions.
解决方案二: 避免相同五元组 DNS 请求的并发
resolv.conf 还有另外两个相关的参数:
- single-request-reopen (since glibc 2.9): A 和 AAAA 请求使用不同的 socket 来发送,这样它们的源 Port 就不同,五元组也就不同,避免了使用同一个 conntrack 表项。
- single-request (since glibc 2.10): A 和 AAAA 请求改成串行,没有并发,从而也避免了冲突。
man resolv.conf 中解释如下:
single-request-reopen (since glibc 2.9)
Sets RES_SNGLKUPREOP in _res.options. The resolver
uses the same socket for the A and AAAA requests. Some
hardware mistakenly sends back only one reply. When
that happens the client system will sit and wait for
the second reply. Turning this option on changes this
behavior so that if two requests from the same port are
not handled correctly it will close the socket and open
a new one before sending the second request.
single-request (since glibc 2.10)
Sets RES_SNGLKUP in _res.options. By default, glibc
performs IPv4 and IPv6 lookups in parallel since
version 2.9. Some appliance DNS servers cannot handle
these queries properly and make the requests time out.
This option disables the behavior and makes glibc
perform the IPv6 and IPv4 requests sequentially (at the
cost of some slowdown of the resolving process).
要给容器的 resolv.conf 加上 options 参数,最方便的是直接在 Pod Spec 里面的 dnsConfig 加 (k8s v1.9 及以上才支持)

spec:
dnsConfig:
options:
- name: single-request-reopen
加 options 还有其它一些方法:
- 在容器的
ENTRYPOINT或者CMD脚本中,执行/bin/echo 'options single-request-reopen' >> /etc/resolv.conf - 在 postStart hook 里加:
lifecycle:
postStart:
exec:
command:
- /bin/sh
- -c
- "/bin/echo 'options single-request-reopen' >> /etc/resolv.conf"
- 使用 MutatingAdmissionWebhook,这是 1.9 引入的 Controller,用于对一个指定的资源的操作之前,对这个资源进行变更。 istio 的自动 sidecar 注入就是用这个功能来实现的,我们也可以通过
MutatingAdmissionWebhook来自动给所有 Pod 注入resolv.conf文件,不过需要一定的开发量。
解决方案三: 使用本地 DNS 缓存
仔细观察可以看到前面两种方案是 glibc 支持的,而基于 alpine 的镜像底层库是 musl libc 不是 glibc,所以即使加了这些 options 也没用,这种情况可以考虑使用本地 DNS 缓存来解决,容器的 DNS 请求都发往本地的 DNS 缓存服务(dnsmasq, nscd, coredns等),不需要走 DNAT,也不会发生 conntrack 冲突。另外还有个好处,就是避免 DNS 服务成为性能瓶颈。
使用本��地DNS缓存有两种方式:
- 每个容器自带一个 DNS 缓存服务
- 每个节点运行一个 DNS 缓存服务,所有容器都把本节点的 DNS 缓存作为自己的 nameserver
从资源效率的角度来考虑的话,推荐后一种方式。
官方也意识到了这个问题比较常见,给出了 coredns 以 cache 模式作为 daemonset 部署的解决方案: https://kubernetes.io/docs/tasks/administer-cluster/nodelocaldns/
Pod 访问另一个集群的 apiserver 有延时
现象:集群 a 的 Pod 内通过 kubectl 访问集群 b 的内网地址,偶尔出现延时的情况,但直接在宿主机上用同样的方法却没有这个问题。
提炼环境和现象精髓:
- 在 pod 内将另一个集群 apiserver 的 ip 写到了 hosts,因为 TKE apiserver 开启内网集群外内网访问创建的内网 LB 暂时没有支持自动绑内网 DNS 域名解析,所以集群外的内网访问 apiserver 需要加 hosts
- pod 内执行 kubectl 访问另一个集群偶尔延迟 5s,有时甚至10s
观察到 5s 延时,感觉跟之前 conntrack 的丢包导致 dns 解析 5s 延时有关,但是加了 hosts 呀,怎么还去解析域名?
进入 pod netns 抓包: 执行 kubectl 时确实有 dns 解析,并且发生延时的时候 dns 请求没有响应然后做了重试。
看起��来延时应该就是之前已知 conntrack 丢包导致 dns 5s 超时重试导致的。但是为什么会去解析域名? 明明配了 hosts 啊,正常情况应该是优先查找 hosts,没找到才去请求 dns 呀,有什么配置可以控制查找顺序?
搜了一下发现: /etc/nsswitch.conf 可以控制,但看有问题的 pod 里没有这个文件。然后观察到有问题的 pod 用的 alpine 镜像,试试其它镜像后发现只有基于 alpine 的镜像才会有这个问题。
再一搜发现: musl libc 并不会使用 /etc/nsswitch.conf ,也就是说 alpine 镜像并没有实现用这个文件控制域名查找优先顺序,瞥了一眼 musl libc 的 gethostbyname 和 getaddrinfo 的实现,看起来也没有读这个文件来控制查找顺序,写死了先查 hosts,没找到再查 dns。
这么说,那还是该先查 hosts 再查 dns 呀,为什么这里抓包看到是先查的 dns? (如果是先查 hosts 就能命中查询,不会再发起dns请求)
访问 apiserver 的 client 是 kubectl,用 go 写的,会不会是 go 程序解析域名时压根没调底层 c 库的 gethostbyname 或 getaddrinfo?

搜一下发现果然是这样: go runtime 用 go 实现了 glibc 的 getaddrinfo 的行为来解析域名,减少了 c 库调用 (应该是考虑到减少 cgo 调用带来的的性能损耗)
issue: net: replicate DNS resolution behaviour of getaddrinfo(glibc) in the go dns resolver
翻源码验证下:
Unix 系的 OS 下,除了 openbsd, go runtime 会读取 /etc/nsswitch.conf (net/conf.go):

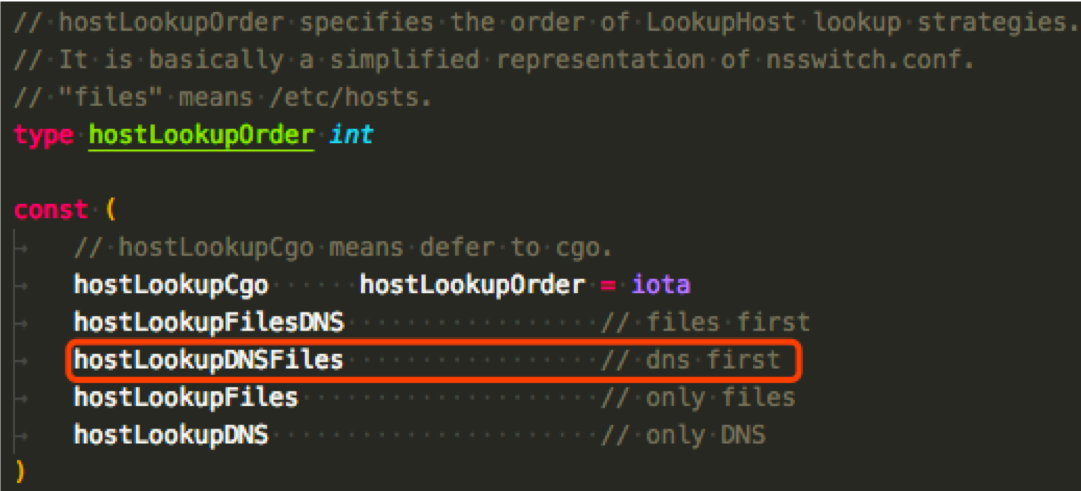
hostLookupOrder 函数决定域名解析顺序的策略,Linux 下,如果没有 nsswitch.conf 文件就 dns 比 hosts 文件优先 (net/conf.go):
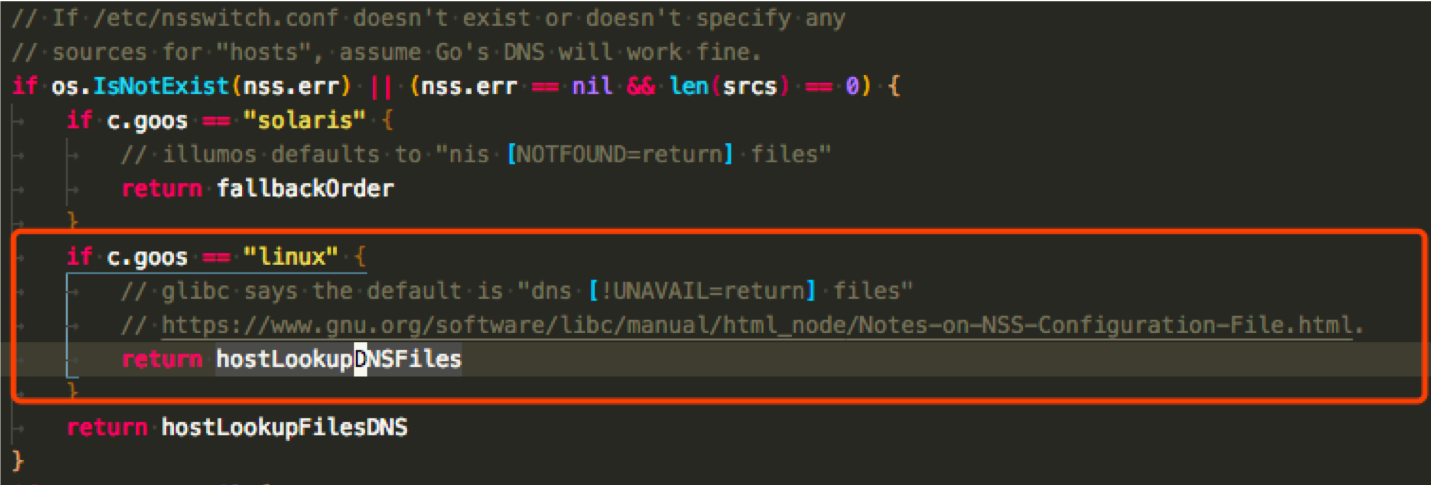
可以看到 hostLookupDNSFiles 的意思是 dns first (net/dnsclient_unix.go):
所以虽然 alpine 用的 musl libc 不是 glibc,但 go 程序解析域名还是一样走的 glibc 的逻辑,而 alpine 没有 /etc/nsswitch.conf 文件,也就解释了为什么 kubectl 访问 apiserver 先做 dns 解析,没解析到再查的 hosts,导致每次访问都去请求 dns,恰好又碰到 conntrack 那个丢包问题导致 dns 5s 延时,在用户这里表现就是 pod 内用 kubectl 访问 apiserver 偶尔出现 5s 延时,有时出现 10s 是因为重试的那次 dns 请求刚好也遇到 conntrack 丢包导致延时又叠加了 5s 。

解决方案:
- 换基础镜像,不用 alpine
- 挂载
nsswitch.conf文件 (可以用 hostPath)
DNS 解析异常
现象: 有个用户反馈域名解析有时有问题,看报错是解析超时。
第一反应当然是看 coredns 的 log:
[ERROR] 2 loginspub.xxxxmobile-inc.net.
A: unreachable backend: read udp 172.16.0.230:43742->10.225.30.181:53: i/o timeout
这是上游 DNS 解析异常了,因为解析外部域名 coredns 默认会请求上游 DNS 来查询,这里的上游 DNS 默认是 coredns pod 所在宿主机的 resolv.conf 里面的 nameserver (coredns pod 的 dnsPolicy 为 "Default",也就是会将宿主机里的 resolv.conf 里的 nameserver 加到容器里的 resolv.conf, coredns 默认配置 proxy . /etc/resolv.conf, 意思是非 service 域名会使用 coredns 容器中 resolv.conf 文件里的 nameserver 来解析)
确认了下,超时的上游 DNS 10.225.30.181 并不是期望的 nameserver,VPC 默认 DNS 应该是 180 开头的。看了 coredns 所在节点的 resolv.conf,发现确实多出了这个非期望的 nameserver,跟用户确认了下,这个 DNS 不是用户自己加上去的,添加节点时这个 nameserver 本身就在 resolv.conf 中。
根据内部同学反馈, 10.225.30.181 是广州一台年久失修将被撤裁的 DNS,物理网络,没有 VIP,撤掉就没有了,所以如果 coredns 用到了这台 DNS 解析时就可能 timeout。后面我们自己测试,某些 VPC 的集群确实会有这个 nameserver,奇了怪了,哪里冒出来的?

又试了下直接创建 CVM,不加进 TKE 节点发现没有这个 nameserver,只要一加进 TKE 节点就有了 !!!
看起来是 TKE 的问题,将 CVM 添加到 TKE 集群会自动重装系统,初始化并加进集群成为 K8S 的 node,确认了初始化过程并不会写 resolv.conf,会不会是 TKE 的 OS 镜像问题?尝试搜一下除了 /etc/resolv.conf 之外哪里还有这个 nameserver 的 IP,最后发现 /etc/resolvconf/resolv.conf.d/base 这里面有。
看下 /etc/resolvconf/resolv.conf.d/base 的作用:Ubuntu 的 /etc/resolv.conf 是动态生成的,每次重启都会将 /etc/resolvconf/resolv.conf.d/base 里面的内容加到 /etc/resolv.conf 里。
经确认: 这个文件确实是 TKE 的 Ubuntu OS 镜像里自带的,可能发布 OS 镜像时不小心加进去的。
那为什么有些 VPC 的集群的节点 /etc/resolv.conf 里面没那个 IP 呢?它们的 OS 镜像里也都有那个文件那个 IP 呀。
请教其它部门同学发现:
- 非 dhcp 子机,cvm 的 cloud-init 会覆盖
/etc/resolv.conf来设置 dns - dhcp 子机,cloud-init 不会设置,而是通过 dhcp 动态下发
- 2018 年 4 月 之后创建的 VPC 就都是 dhcp 类型了的,比较新的 VPC 都是 dhcp 类型的
真相大白:/etc/resolv.conf 一开始内容都包含 /etc/resolvconf/resolv.conf.d/base 的内容,也就是都有那个不期望的 nameserver,但老的 VPC 由于不是 dhcp 类型,所以 cloud-init 会覆盖 /etc/resolv.conf,抹掉了不被期望的 nameserver,而新创建的 VPC 都是 dhcp 类型,cloud-init 不会覆盖 /etc/resolv.conf,导致不被期望的 nameserver 残留在了 /etc/resolv.conf,而 coredns pod 的 dnsPolicy 为 “Default”,也就是会将宿主机的 /etc/resolv.conf 中的 nameserver 加到容器里,coredns 解析集群外的域名默认使用这些 nameserver 来解析,当用到那个将被撤裁的 nameserver 就可能 timeout。
临时解决: 删掉 /etc/resolvconf/resolv.conf.d/base 重启
长期解决: 我们重新制作 TKE Ubuntu OS 镜像然后发布更新
这下应该没问题了吧,But, 用户反馈还是会偶尔解析有问题,但现象不一样了,这次并不是 dns timeout。

用脚本跑测试仔细分析现象:
- 请求
loginspub.xxxxmobile-inc.net时,偶尔提示域名无法解析 - 请求
accounts.google.com时,偶尔提示连接失败
进入 dns 解析偶尔异常的容器的 netns 抓包:
- dns 请求会并发请求 A 和 AAAA 记录
- 测试脚本发请求打印序号,抓包然后 wireshark 分析对��比异常时请求序号偏移量,找到异常时的 dns 请求报文,发现异常时 A 和 AAAA 记录的请求 id 冲突,并且 AAAA 响应先返回

正常情况下id不会冲突,这里冲突了也就能解释这个 dns 解析异常的现象了:
loginspub.xxxxmobile-inc.net没有 AAAA (ipv6) 记录,它的响应先返回告知 client 不存在此记录,由于请求 id 跟 A 记录请求冲突,后面 A 记录响应返回了 client 发现 id 重复就忽略了,然后认为这个域名无法解析accounts.google.com有 AAAA 记录,响应先返回了,client 就拿这个记录去尝试请求,但当前容器环境不支持 ipv6,所以会连接失败
那为什么 dns 请求 id 会冲突?

继续观察发现: 其它节点上的 pod 不会复现这个问题,有问题这个节点上也不是所有 pod 都有这个问题,只有基于 alpine 镜像的容器才有这个问题,在此节点新起一个测试的 alpine:latest 的容器也一样有这个问题。
为什么 alpine 镜像的容器在这个节点上有问题在其它节点上没问题? 为什么其他镜像的容器都没问题?它们跟 alpine 的区别是什么?
发现一点区别: alpine 使用的底层 c 库是 musl libc,其它镜像基本都是 glibc
翻 musl libc 源码, 构造 dns 请求时,请求 id 的生成没加锁,而且跟当前时间戳有关:

看注释,作者应该认为这样id基��本不会冲突,事实证明,绝大多数情况确实不会冲突,我在网上搜了很久没有搜到任何关于 musl libc 的 dns 请求 id 冲突的情况。这个看起来取决于硬件,可能在某种类型硬件的机器上运行,短时间内生成的 id 就可能冲突。我尝试跟用户在相同地域的集群,添加相同配置相同机型的节点,也复现了这个问题,但后来删除再添加时又不能复现了,看起来后面新建的 cvm 又跑在了另一种硬件的母机上了。
OK,能解释通了,再底层的细节就不清楚了,我们来看下解决方案:
- 换基础镜像 (不用alpine)
- 完全静态编译业务程序(不依赖底层c库),比如go语言程序编译时可以关闭 cgo (CGO_ENABLED=0),并告诉链接器要静态链接 (
go build后面加-ldflags '-d'),但这需要语言和编译工具支持才可以
最终建议用户基础镜像换成另一个比较小的镜像: debian:stretch-slim。
Pod 偶尔存活检查失败
现象: Pod 偶尔会存活检查失败,导致 Pod 重启,业务偶尔连接异常。
之前从未遇到这种情况,在自己测试环境尝试复现也没有成功,只有在用户这个环境才可以复现。这个用户环境流量较大,感觉跟连接数或并发量有关。
用户反馈说在友商的环境里没这个问题。
对比友商的内核参数发现有些区别,尝试将节点内核参数改成跟友商的一样,发现问题没有复现了。
再对比分析下内核参数差异,最后发现是 backlog 太小导致的,节点的 net.ipv4.tcp_max_syn_backlog 默认是 1024,如果短时间内并发新建 TCP 连接太多,SYN 队列就可能溢出,导致部分新连接无法建立。
解释一下:
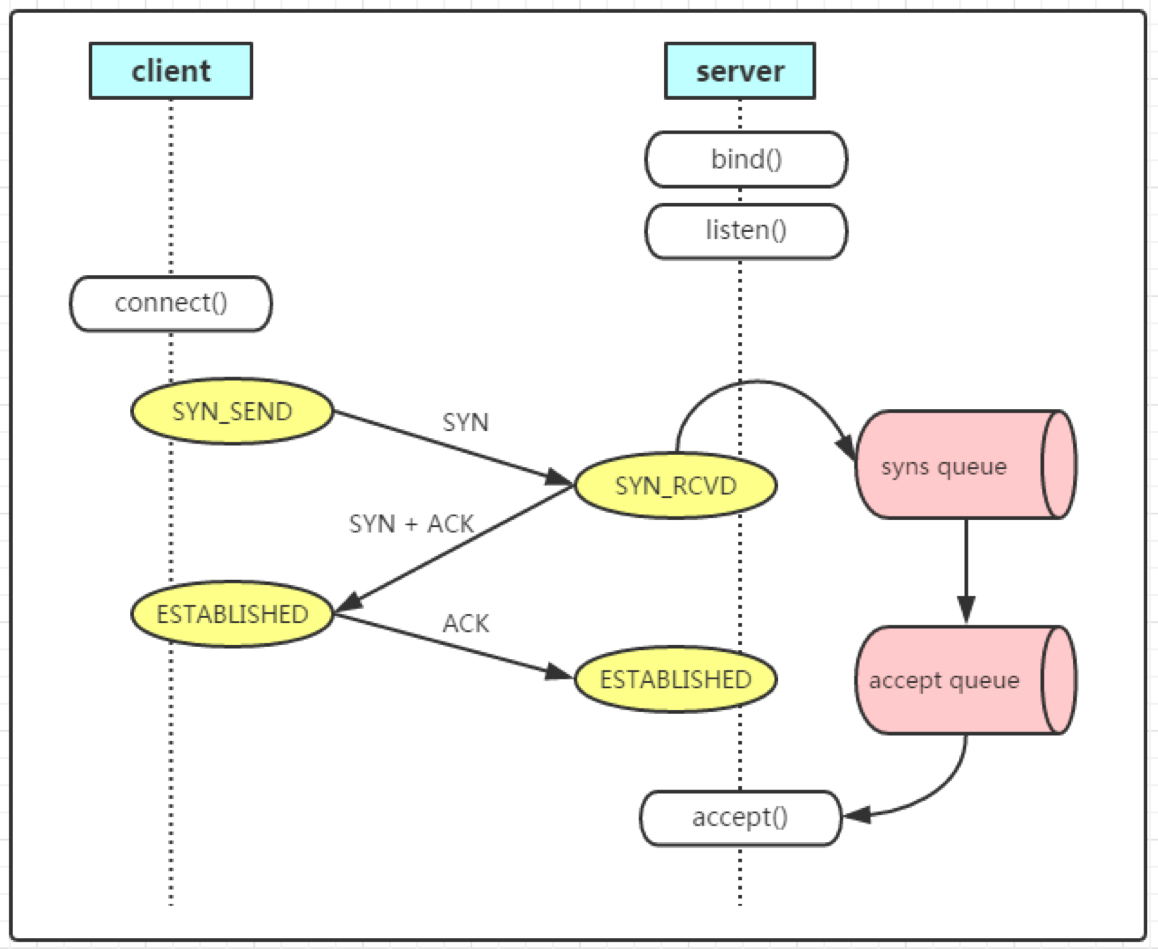
TCP 连接建立会经过三次握手,server 收到 SYN 后会将连接加入 SYN 队列,当收到最后一个 ACK 后连接建立,这时会将连接从 SYN 队列中移动到 ACCEPT 队列。在 SYN 队列中的连接都是没有建立完全的连接,处于半连接状态。如果 SYN 队列比较小,而短时间内并发新建的连接比较多,同时处于半连接状态的连接就多,SYN 队列就可能溢出,tcp_max_syn_backlog 可以控制 SYN 队列大小,用户节点的 backlog 大小默认是 1024,改成 8096 后就可以解决问题。
访问 externalTrafficPolicy 为 Local 的 Service 对应 LB 有时超时
现象:用户在 TKE 创建了公网 LoadBalancer 类型的 Service,externalTrafficPolicy 设为了 Local,访问这个 Service 对应的公网 LB 有时会超时。
externalTrafficPolicy 为 Local 的 Service 用于在四层获取客户端真实源 IP,官方参考文档:Source IP for Services with Type=LoadBalancer
TKE 的 LoadBalancer 类型 Service 实现是使用 CLB 绑定所有节点对应 Service 的 NodePort,CLB 不做 SNAT,报文转发到 NodePort 时源 IP 还是真实的客户端 IP,如果 NodePort 对应 Service 的 externalTrafficPolicy 不是 Local 的就会做 SNAT,到 pod 时就看不到客户端真实源 IP 了,但如果是 Local 的话就不做 SNAT,如果本机 node 有这个 Service 的 endpoint 就转到对应 pod,如果没有就直接丢掉,因为如果转到其它 node 上的 pod 就必须要做 SNAT,不然无法回包,而 SNAT 之后就无法获取真实源 IP 了。
LB 会对绑定节点的 NodePort 做健康检查探测,检查 LB 的健康检查状态: 发现这个 NodePort 的所有节点都不健康 !!!

那么问题来了:
- 为什么会全不健康,这个 Service 有对应的 pod 实例,有些节点上是有 endpoint 的,为什么它们也不健康?
- LB 健康检查全不健康,但是为什么有时还是可以访问后端服务?

跟 LB 的同学确认: 如果后端 rs 全不健康会激活 LB 的全死全活逻辑,也就是所有后端 rs 都可以转发。
那么有 endpoint 的 node 也是不健康这个怎么解释?
在有 endpoint 的 node 上抓 NodePort 的包: 发现很多来自 LB 的 SYN,但是没有响应 ACK。
看起来报文在哪被丢了,继续抓下 cbr0 看下: 发现没有来自 LB 的包,说明报文在 cbr0 之前被丢了。
再观察用户集群环境信息:
- k8s 版本1.12
- 启用了 ipvs
- 只有 local 的 service 才有异常
尝试新建一个 1.12 启用 ipvs 和一个没启用 ipvs 的测试集群。也都创建 Local 的 LoadBalancer Service,发现启用 ipvs 的测试集群复现了那个问题,没启用 ipvs 的集群没这个问题。
再尝试创建 1.10 的集群,也启用 ipvs,发现没这个问题。
看起来跟集群版本和是否启用 ipvs 有关。
1.12 对比 1.10 启用 ipvs 的集群: 1.12 的会将 LB 的 EXTERNAL-IP 绑到 kube-ipvs0 上,而 1.10 的不会:
$ ip a show kube-ipvs0 | grep -A2 170.106.134.124
inet 170.106.134.124/32 brd 170.106.134.124 scope global kube-ipvs0
valid_lft forever preferred_lft forever
- 170.106.134.124 是 LB 的公网 IP
- 1.12 启用 ipvs 的集群将 LB 的公网 IP 绑到了
kube-ipvs0网卡上
kube-ipvs0 是一个 dummy interface,实际不会接收报文,可以看到它的网卡状态是 DOWN,主要用于绑 ipvs 规则的 VIP,因为 ipvs 主要工作在 netfilter 的 INPUT 链,报文通过 PREROUTING 链之后需要决定下一步该进入 INPUT 还是 FORWARD 链,如果是本机 IP 就会进入 INPUT,如果不是就会进入 FORWARD 转发到其它机器。所以 k8s 利用 kube-ipvs0 这个网卡将 service 相关的 VIP 绑在上面以便让报文进入 INPUT 进而被 ipvs 转发。
当 IP 被绑到 kube-ipvs0 上,内核会自动将上面的 IP 写入 local 路由:
$ ip route show table local | grep 170.106.134.124
local 170.106.134.124 dev kube-ipvs0 proto kernel scope host src 170.106.134.124
内核认为在 local 路由里的 IP 是本机 IP,而 linux 默认有个行为: 忽略任何来自非回环网卡并且源 IP 是本机 IP 的报文。而 LB 的探测报文源 IP 就是 LB IP,也就是 Service 的 EXTERNAL-IP 猜想就是因为这个 IP 被绑到 kube-ipvs0,自动加进 local 路由导致内核直接忽略了 LB 的探测报文。
带着猜想做实现, 试一下将 LB IP 从 local 路由中删除:
ip route del table local local 170.106.134.124 dev kube-ipvs0 proto kernel scope host src 170.106.134.124
发现这个 node 的在 LB 的健康检查的状态变成健康了! 看来就是因为这个 LB IP 被绑到 kube-ipvs0 导致内核忽略了来自 LB 的探测报文,然后 LB 收不到回包认为不健康。
那为什么其它厂商没反馈这个问题?应该是 LB 的实现问题,腾讯云的公网 CLB 的健康探测报文源 IP 就是 LB 的公网 IP,而大多数厂商的 LB 探测报文源 IP 是保留 IP 并非 LB 自身的 VIP。
如何解决呢? 发现一个内核参数: accept_local 可以让 linux 接收源 IP 是本机 IP 的报文。
试了开启这个参数,确实在 cbr0 收到来自 LB 的探测报文了,说明报文能被 pod 收到,但抓 eth0 还是没有给 LB 回包。

为什么没有回包? 分析下五元组,要给 LB 回包,那么 目的IP:目的Port 必须是探测报文的 源IP:源Port,所以目的 IP 就是 LB IP,由于容器不在主 netns,发包经过 veth pair 到 cbr0 之后需要再经过 netfilter 处理,报文进入 PREROUTING 链然后发现目的 IP 是本机 IP,进入 INPUT 链,所以报文就出不去了。再分析下进入 INPUT 后会怎样,因为目的 Port 跟 LB 探测报文源 Port 相同,是一个随机端口,不在 Service 的端口列表,所以没有对应的 IPVS 规则,IPVS 也就不会转发它,而 kube-ipvs0 上虽然绑了这个 IP,但它是一个 dummy interface,不会收包,所以报文最后又被忽略了。
再看看为什么 1.12 启用 ipvs 会绑 EXTERNAL-IP 到 kube-ipvs0,翻翻 k8s 的 kube-proxy 支持 ipvs 的 proposal,发现有个地方说法有点漏洞:

LB 类型 Service 的 status 里有 ingress IP,实际就是 kubectl get service 看到的 EXTERNAL-IP,这里说不会绑定这个 IP 到 kube-ipvs0,但后面又说会给它创建 ipvs 规则,既然没有绑到 kube-ipvs0,那么这�个 IP 的报文根本不会进入 INPUT 被 ipvs 模块转发,创建的 ipvs 规则也是没用的。
后来找到作者私聊,思考了下,发现设计上确实有这个问题。
看了下 1.10 确实也是这么实现的,但是为什么 1.12 又绑了这个 IP 呢? 调研后发现是因为 #59976 这个 issue 发现一个问题,后来引入 #63066 这个 PR 修复的,而这个 PR 的行为就是让 LB IP 绑到 kube-ipvs0,这个提交影响 1.11 及其之后的版本。
#59976 的问题是因为没绑 LB IP到 kube-ipvs0 上,在自建集群使用 MetalLB 来实现 LoadBalancer 类型的 Service,而有些网络环境下,pod 是无法直接访问 LB 的,导致 pod 访问 LB IP 时访问不了,而如果将 LB IP 绑到 kube-ipvs0 上就可以通过 ipvs 转发到 LB 类型 Service 对应的 pod 去, 而不需要真正经过 LB,所以引入了 #63066 这个PR。
临时方案: 将 #63066 这个 PR 的更改回滚下,重新编译 kube-proxy,提供升级脚本升级存量 kube-proxy。
如果是让 LB 健康检查探测支持用保留 IP 而不是自身的公网 IP ,也是可以解决,但需要跨团队合作,而且如果多个厂商都遇到这个问题,每家都需要为解决这个问题而做开发调整,代价较高,所以长期方案需要跟社区沟通一起推进,所以我提了 issue,将问题描述的很清楚: #79783
小思考: 为什么 CLB 可以不做 SNAT ? 回包目的 IP 就是真实客户端 IP,但客户端是直接跟 LB IP 建立的连接,如果回包不经过 LB 是不可能发送成功的呀。
是因为 CLB 的实现是在母机上通过隧道跟 CVM 互联的,多了一层封装,回包始终会经过 LB。
就是因为 CLB 不做 SNAT,正常来自客户端的报文是可以发送到 nodeport,但健康检查探测报文由于源 IP 是 LB IP 被绑到 kube-ipvs0 导致被忽略,也就解释了为什么健康检查失败,但通过LB能访问后端服务,只是有时会超时。那么如果要做 SNAT 的 LB 岂不是更糟糕,所有报文都变成 LB IP,所有报文都会被忽略?
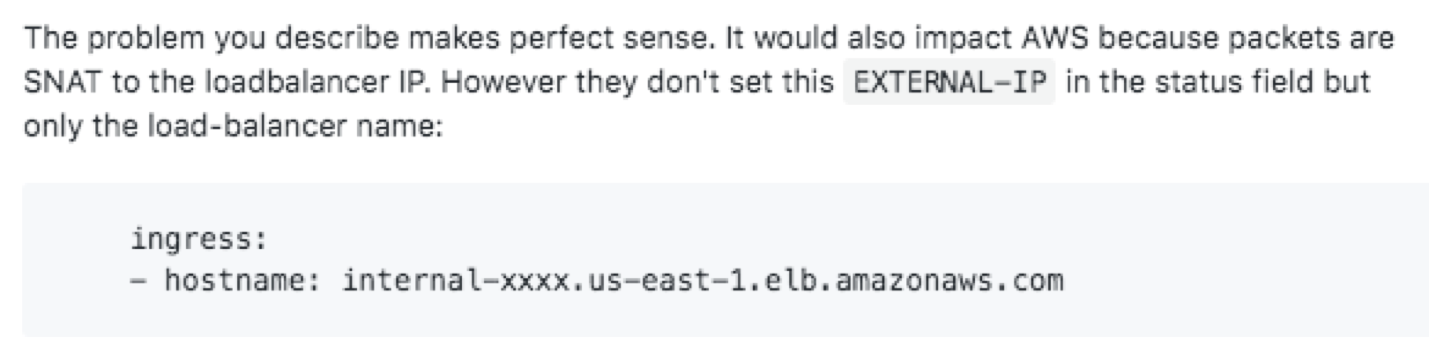
我提的 issue 有回复指出,AWS 的 LB 会做 SNAT,但它们不将 LB 的 IP 写到 Service 的 Status 里,只写了 hostname,所以也不会绑 LB IP 到 kube-ipvs0:
但是只写 hostname 也得 LB 支持自动绑域名解析,并且个人觉得只写 hostname 很别扭,通过 kubectl get svc 或者其它 k8s 管理系统无法直接获取 LB IP,这不是一个好的解决方法。
我提了 #79976 这个 PR 可以解决问题: 给 kube-proxy 加 --exclude-external-ip 这个 flag 控制是否为 LB IP
创建 ipvs 规则和绑定 kube-ipvs0。
但有人担心增加 kube-proxy flag 会增加 kube-proxy 的调试复杂度,看能否在 iptables 层面解决:
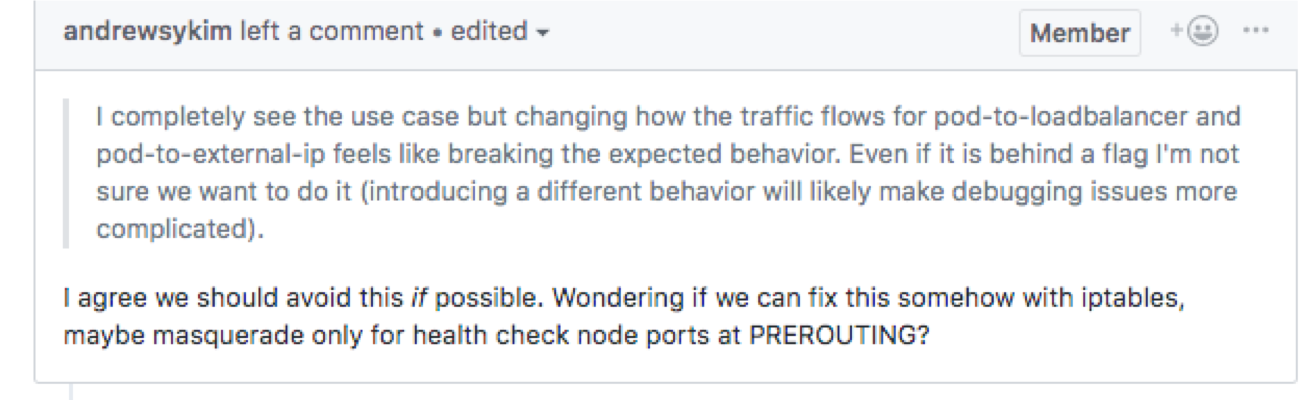
仔�细一想,确实可行,打算有空实现下,重新提个 PR:

结语
至此,我们一起完成了一段奇妙的问题排查之旅,信息量很大并且比较复杂,有些没看懂很正常,但我希望你可以收藏起来反复阅读,一起在技术的道路上打怪升级。