梳理进程发包流程
概述
进程向外发送数据,通常通过系统调用 sendto 来实现,下面基于 Linux 6.14 的代码来分析一下 sendto 的实现。
整体流程
应用发包的整体流程如下:
应用程序 --> 系统调用 --> 传输层 --> 网络层 --> 数据链路层 --> 网络设备子系统 --> 网络设备驱动 --> 网络硬件
除去首尾,中间部分全是 linux 内核的逻辑,下面针对这些流程对内核代码进行详细的梳理和分析。
系统调用入口
代码流程:
// file: net/socket.c
SYSCALL_DEFINE6(sendto, ...) // 声明系统调用
|
+-- __sys_sendto(...) // 系统调用入口
|
+-- __sock_sendmsg(...) // 进入协议栈
|
+-- sock_sendmsg_nosec(...)
|
+-- sk->ops->sendmsg // 丢给传输层处理
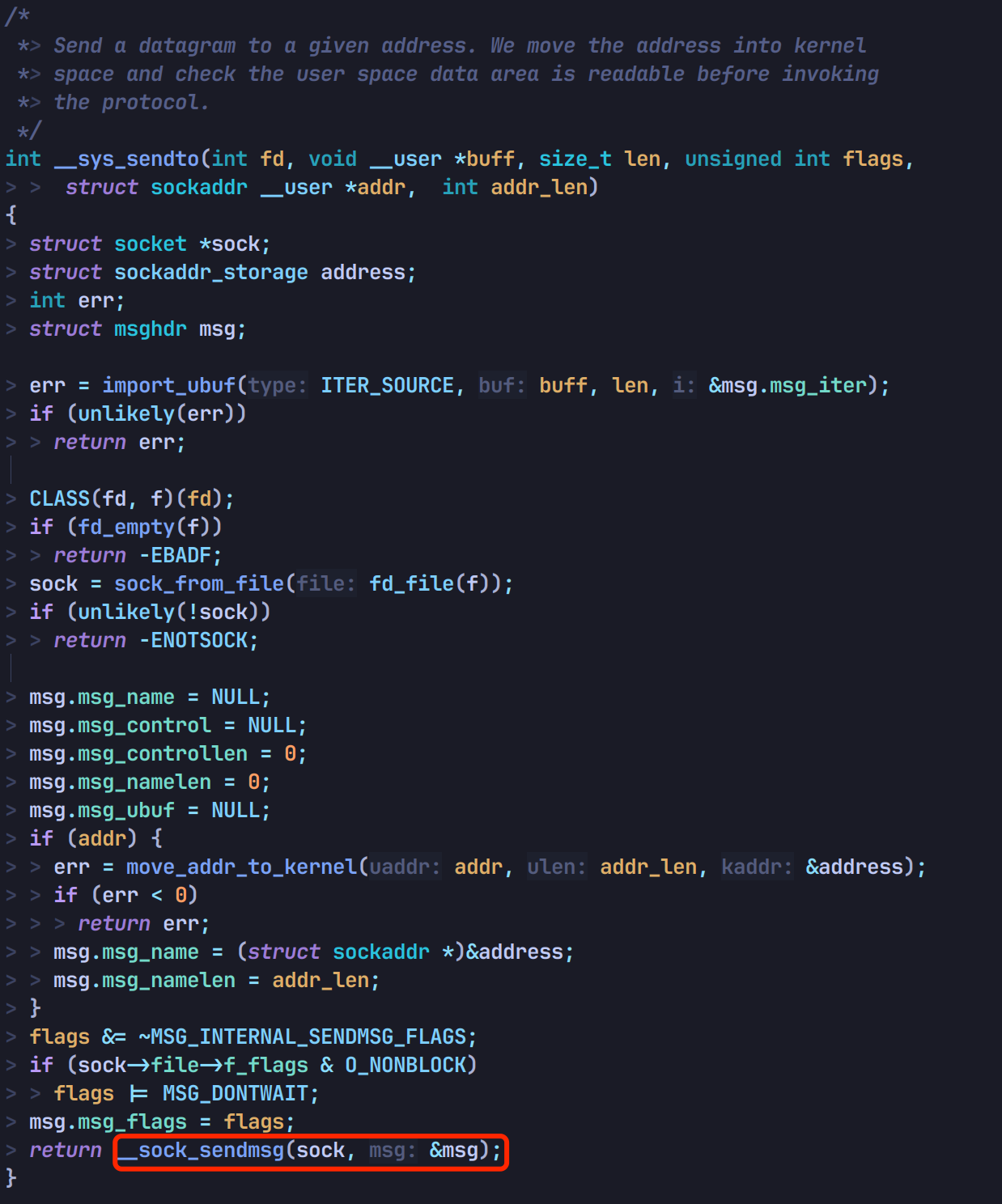
net/socket.c 中定义了 sendto 的系统调用:

跳转 __sys_sendto,走到 __sock_sendmsg:
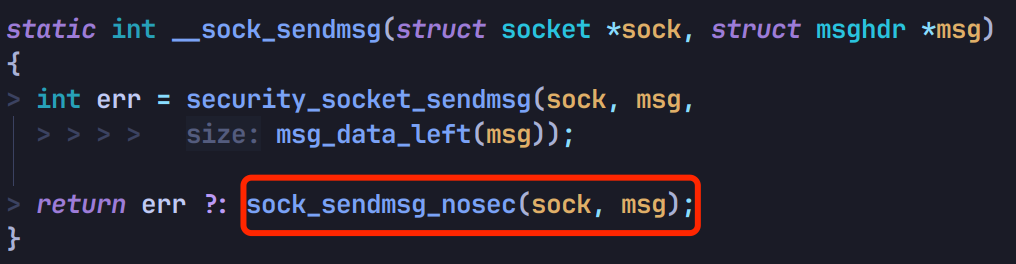
继续走到 sock_sendmsg_nosec:
接着会调用数据包对应协议的 sendmsg 函数将包丢给传输层处理:

传输层
代码流程:
// file: net/ipv4/af_inet.c
inet_sendmsg(...) // 传输层入口, 对应系统调用函数中的 sk->ops->sendmsg
| // file: net/ipv4/tcp.c
+-- tcp_sendmsg(...) // 对应 sk->sk_prot->sendmsg(sock->sk, msg, size)
|
+-- tcp_sendmsg_locked(...)
|
+-- tcp_push(...)
|
+-- __tcp_push_pending_frames(...)
|
+-- tcp_write_xmit(...)
|
+-- tcp_transmit_skb(...)
|
+-- __tcp_transmit_skb(...)
|
+-- icsk->icsk_af_ops->queue_xmit // 丢给 IP 层 处理
看下 sendmsg 的实现,在 net/ipv4/af_inet.c 中可以看到 IPv4 的 stream 类型实现对应的是 inet_sendmsg 函数:
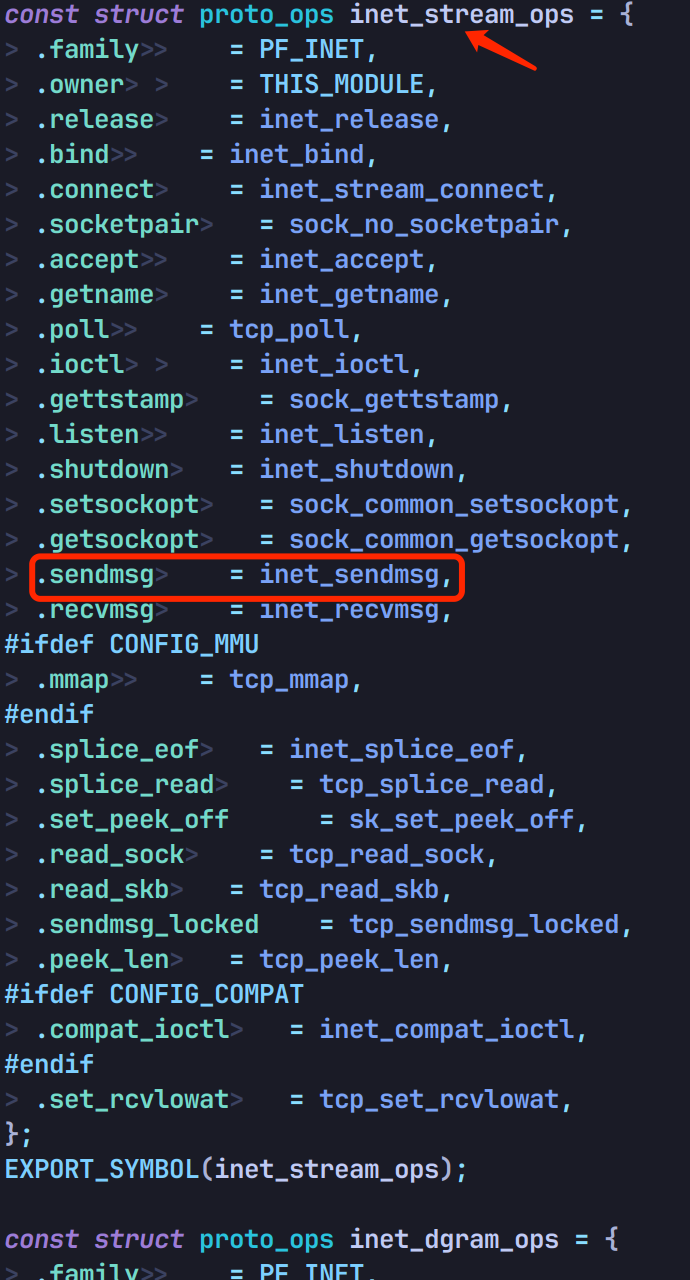
继续往下看,inet_sendmsg 会调用 sk->sk_prot->sendmsg 发包:

TCP 协议的情况下,会使用 tcp_sendmsg 这个函数,从 net/ipv4/tcp_ipv4.c 中 tcp_prot 的赋值可以看出:

继续调用 tcp_sendmsg_locked:

再调用 tcp_push:
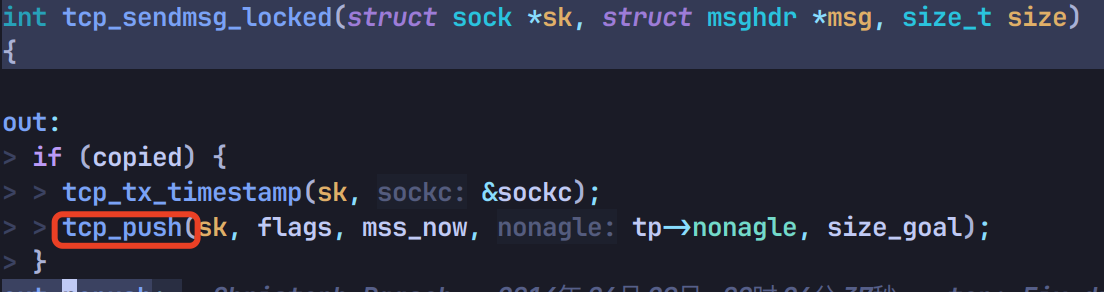
底部调用 __tcp_push_pending_frames:

继续调用 tcp_write_xmit:
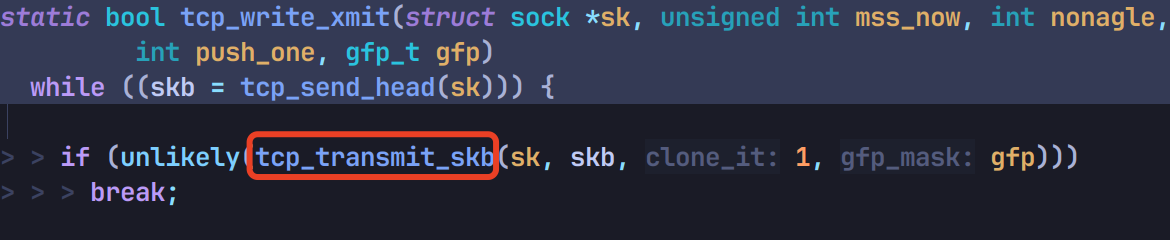
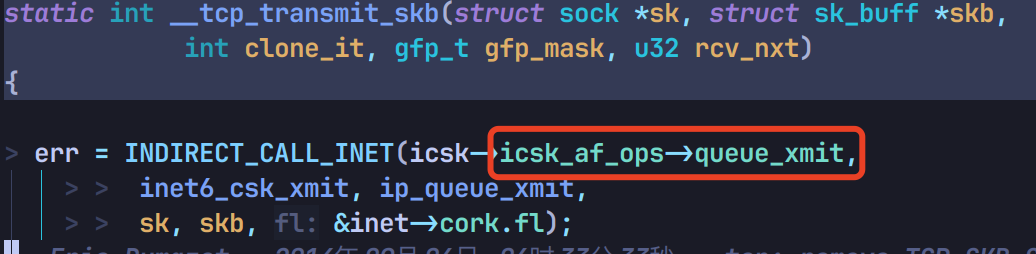
再调用 tcp_transmit_skb 和 __tcp_transmit_skb:

走到 icsk->icsk_af_ops->queue_xmit,将包丢给 IP 层处理:
网络层
代码流程:
// file: net/ipv4/ip_output.c
ip_queue_xmit(...) // 网络层入口,对应传输层中 icsk->icsk_af_ops->queue_xmit 的函数引用
|
+-- __ip_queue_xmit(...)
|
+-- ip_local_out(...)
|
+-- __ip_local_out(...)
| |
| +-- nf_hook(NFPROTO_IPV4, NF_INET_LOCAL_OUT, ...) // 调用 OUTPUT 链钩子函数
| // file: include/net/dst.h
+-- dst_output(...)
| // file: net/ipv4/ip_output.c
+-- ip_outpout(...) // 对应 skb_dst(skb)->output
|
+-- NF_HOOK_COND(NFPROTO_IPV4, NF_INET_POST_ROUTING, ... , ip_finish_output, ...) // 调用 POSTROUTING 链钩子函数,如果没丢包会继续调用 ip_finish_output
|
+-- ip_finish_output(...)
|
+-- __ip_finish_output(...)
|
+-- ip_finish_output2(...)
|
+-- ip_neigh_for_gw(...) // arp 查询 mac 地址
|
+-- neigh_output(...) // 丢给数据链路层处理
传输层中 icsk->icsk_af_ops->queue_xmit 的函数引用的 IPv4 实现在 net/ipv4/tcp_ipv4.c 中有声明,是 ip_queue_xmit 这个函数:
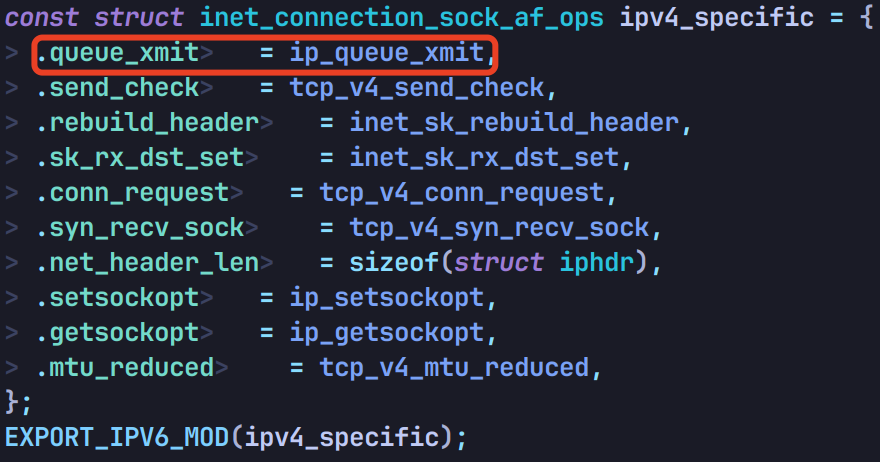
进入这个函数,它直接调用 __ip_queue_xmit:

走到 ip_local_out:
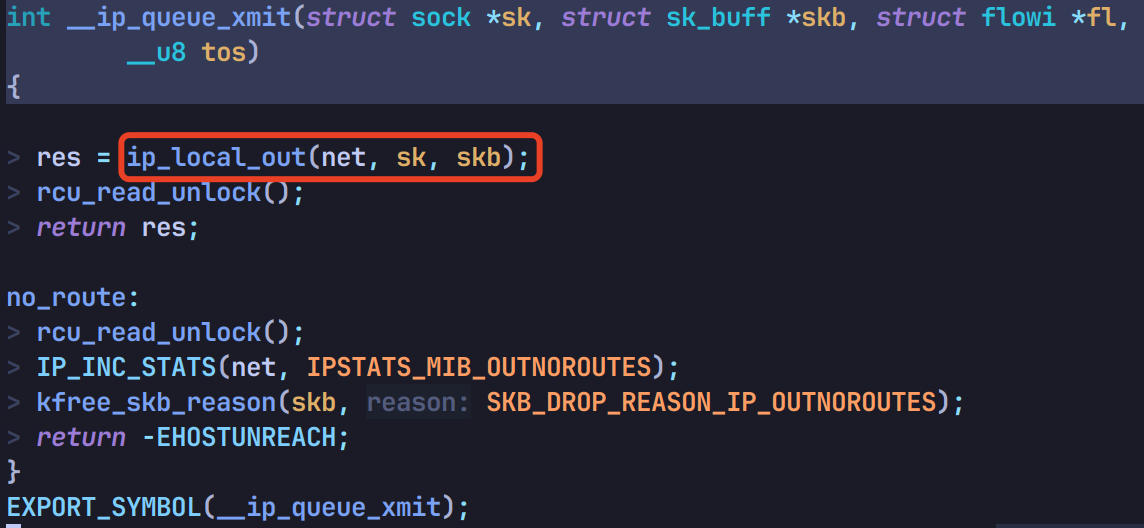
先调用 __ip_local_out,再调用 dst_output:
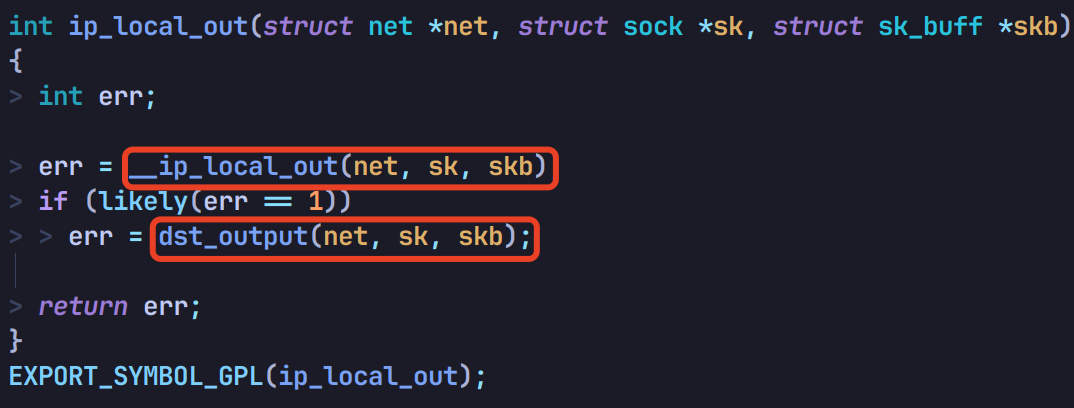
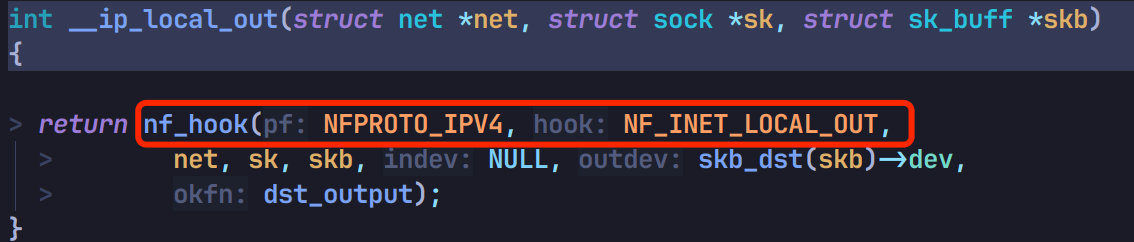
其中 __ip_local_out 会通过 nf_hook 调用 OUTPUT 链的钩子函数:
如果没丢包,继续走到 dst_output 调用 skb_dst(skb)->output:

这个 outpout 函数实际对应 ip_outpout 函数,里面会调用 POSTROUTING 链的钩子函数,如果没丢包会继续调用 ip_finish_output:
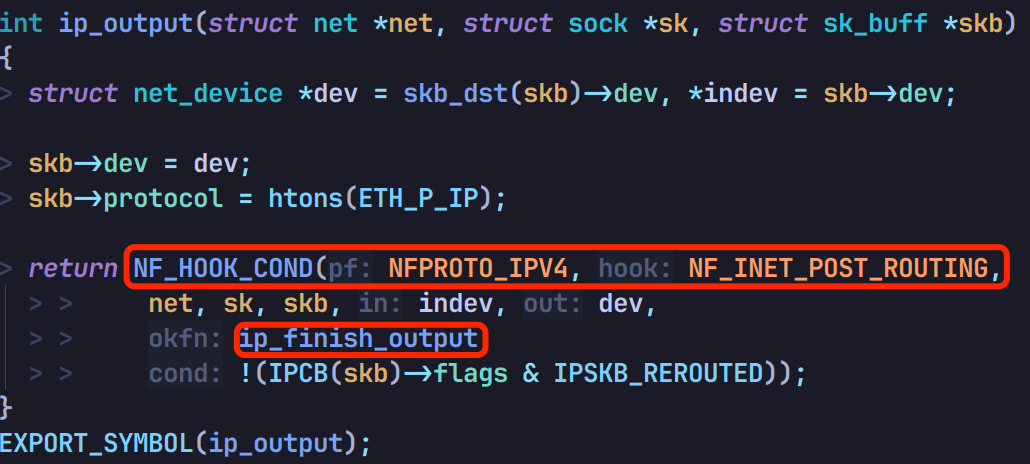
然后调用 __ip_finish_output:
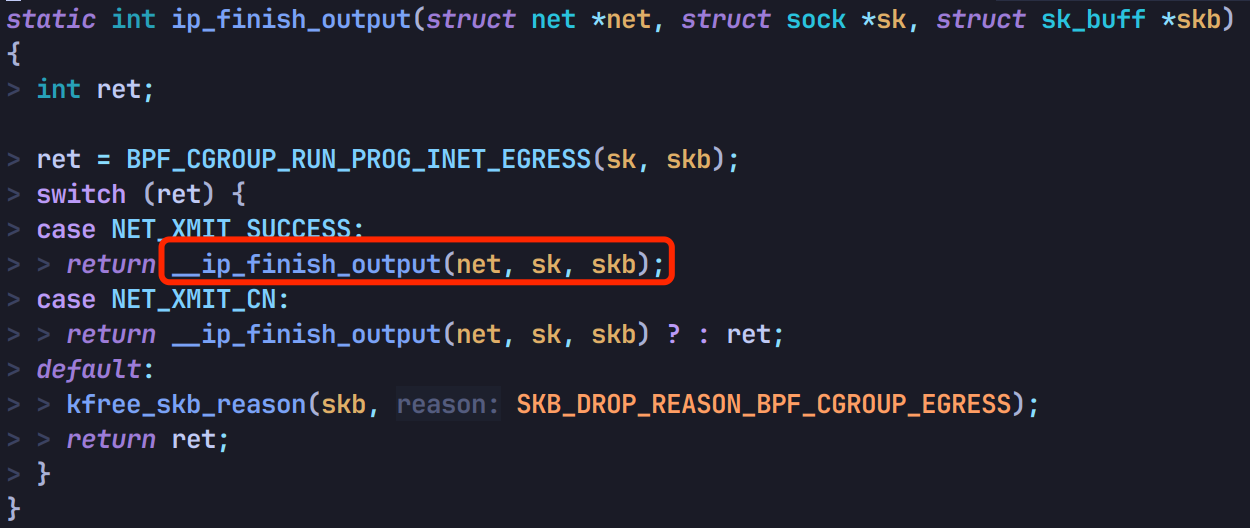
接着调 ip_finish_output2:
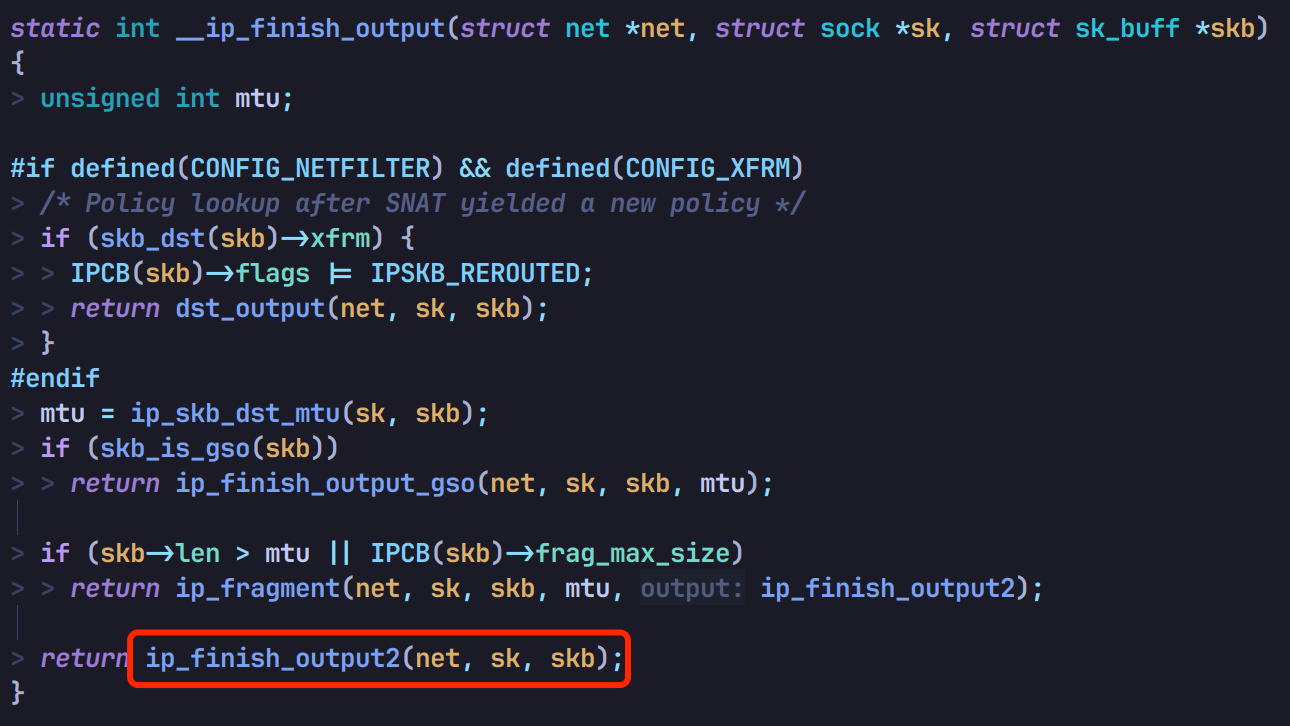
然后先调 ip_neigh_for_gw 通过 arp 查 mac 地址,再调 neigh_output 丢给数据链路层处理:

数据链路层
代码流程:
// file: include/net/neighbour.h
neigh_output(...)
|
+-- neigh_hh_output(...)
|
+-- dev_queue_xmit(...) // 调用网络设备子系统处理
在 neigh_output 中,调用 neigh_hh_output:

最后调用 dev_queue_xmit 丢给网络设备子系统处理:

网络设备子系统
代码流程:
// file: include/linux/netdevice.h
dev_queue_xmit(...)
| // file: net/core/dev.c
+-- __dev_queue_xmit(...)
|
+-- __dev_xmit_skb(...) // 如需排队,交给 qdisc 排队发送
|
+-- dev_hard_start_xmit(...)// 如无需排队,直接发送
|
+-- xmit_one(...)
| // file: include/linux/netdevice.h
+-- netdev_start_xmit(...)
|
+-- ops->ndo_start_xmit(skb, dev) // 调用网络设备驱动发送数据包
在 dev_queue_xmit 中,直接调用 __dev_queue_xmit:

如果需要排队,走 __dev_xmit_skb,如果不需要排队,直接调 dev_hard_start_xmit 发送:
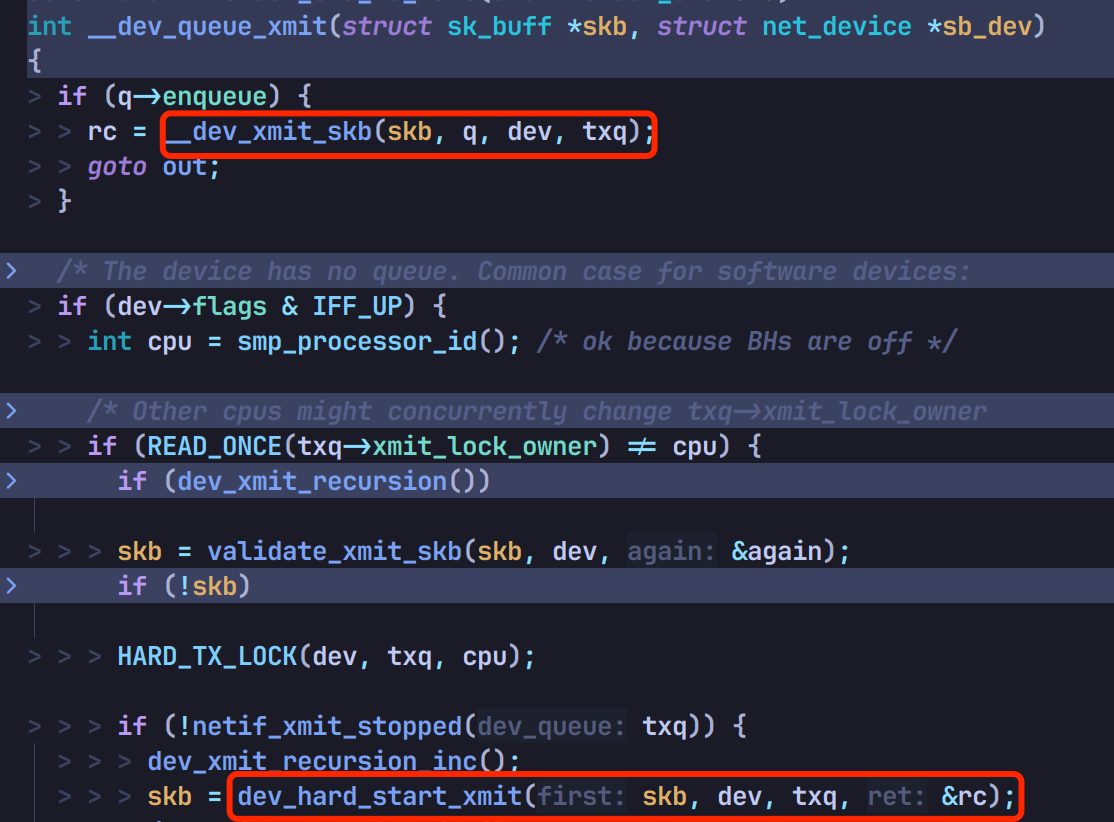
调用 xmit_one:

再调用 netdev_start_xmit:

进一步调用 __netdev_start_xmit:

最后通过调用 ops->ndo_start_xmit(skb, dev) 将数据包丢给网络设备驱动处理:

网络设备驱动
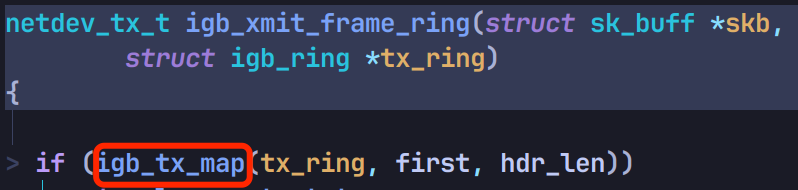
ndo_start_xmit 是网络设备驱动需实现的函数,以 intel 的 igb 驱动所支持的网卡为例,找到驱动的实现函数为 igb_xmit_frame:

代码流程:
// file: drivers/net/ethernet/intel/igb/igb_main.c
igb_xmit_frame(...) // intel igb 网卡驱动的实现函数
|
+-- igb_xmit_frame_ring(...)
|
+-- igb_tx_map(...) // 将数据丢给网卡转发
调用 igb_xmit_frame_ring:
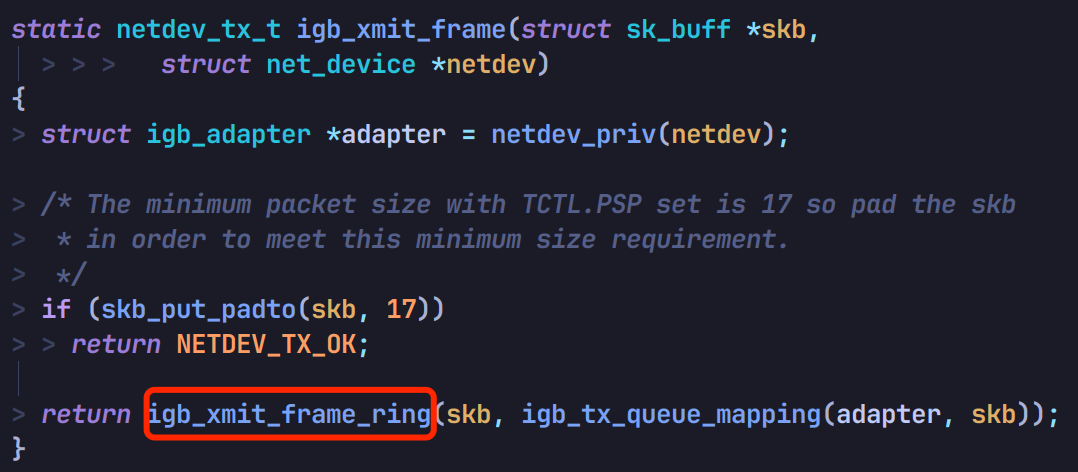
再调用 igb_tx_map 将数据丢给网卡转发: