Serverless Elastic Cluster Notes
Accessing Public Network
Unlike TKE clusters, EKS has no nodes, so Pods cannot utilize the node's own public network bandwidth to access the public internet like in TKE.
Since EKS has no nodes, there are two ways to allow Pods to access the public internet:
In most cases, consider method one: create a NAT gateway, configure routing in the VPC routing table. If you want the entire VPC to default to using this NAT gateway for public internet access, you can modify the default routing table:

If you only want Pods on super nodes to use this NAT gateway, create a new routing table.
The configuration method is to create a new routing policy in the routing table, with the 0.0.0.0/0 segment's next hop type as NAT Gateway, and select the NAT gateway instance created earlier:
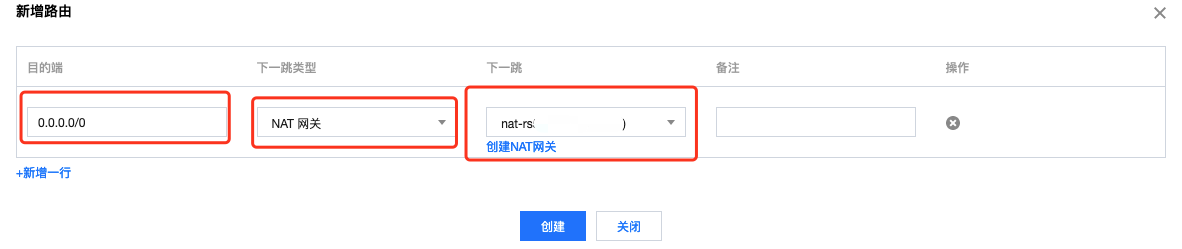
After creation, if it's not the default routing table, you need to associate it with the super node's subnet:

Port 9100
EKS by default listens on port 9100 of each Pod, exposing Pod-related monitoring metrics. If your business itself also listens on port 9100, it will fail. Refer to Port 9100 Issue.
Pay Attention to Quota Limits
When using EKS clusters, pay attention to the following quota limits. If insufficient, you can submit a support ticket to increase the upper limit:
- Maximum number of Pods per cluster (default 200).
- Maximum number of instances bound to a security group (if you don't specify a security group for Pods, the default security group for the current project in the current region will be used, with a maximum of 2000 instances per security group).
ipvs Timeout Issues
istio Scenario DNS Timeout
istio's sidecar (istio-proxy) intercepts traffic using conntrack for connection tracking. When some non-intercepted traffic (such as UDP) accesses through service, it goes through ipvs forwarding. Both ipvs and conntrack have timeout settings for connections. If the timeout times in ipvs and conntrack are inconsistent, it may result in the connection still existing in conntrack but being cleaned up in ipvs, causing outgoing packets to be scheduled to new backend servers by ipvs. When the backend server responds, it doesn't match conntrack and won't perform reverse SNAT, causing the process to not receive the response.
In EKS, the ipvs timeout is currently defaulted to 5s, while conntrack timeout is defaulted to 120s. If you use TCM or install istio yourself in EKS, when coredns scales up after some time, business domain name resolution may experience DNS timeouts.
Before a productized solution is available, we can add the following annotation to Pods to set the ipvs timeout to 120s, aligning it with the conntrack timeout:
eks.tke.cloud.tencent.com/ipvs-udp-timeout: "120s"
gRPC Scenario Connection reset by peer
gRPC uses long connections. The Java version of gRPC has a default idle timeout of 30 minutes and doesn't configure TCP connection keepalive heartbeats, while ipvs has a default tcp timeout of 15 minutes.
This causes a problem: After business is idle for 15 minutes, ipvs disconnects, but the upper application still thinks the connection is active and will reuse the connection to send packets. However, the corresponding connection in ipvs no longer exists, and it will directly respond with RST to disconnect the connection. From the business log perspective, this appears as Connection reset by peer.
In this situation, if you don't want to modify code to enable keepalive, you can directly adjust the eks ipvs tcp timeout time to match the business idle timeout duration:
eks.tke.cloud.tencent.com/ipvs-tcp-timeout: "1800s"