Understanding KEDA
What is KEDA?
KEDA (Kubernetes-based Event-Driven Autoscaler) is an event-driven autoscaler in Kubernetes with very powerful capabilities. It not only supports scaling based on basic CPU and memory metrics, but also based on various message queue lengths, database statistics, QPS, Cron schedules, and any other metrics you can imagine. It can even scale replicas down to 0.
The project was accepted by CNCF in March 2020, started incubation in August 2021, and finally announced graduation in August 2023. It is now very mature and can be confidently used in production environments.
Why is KEDA Needed?
HPA is Kubernetes' built-in horizontal pod autoscaler, which can only automatically scale workloads based on monitoring metrics, mainly CPU and memory utilization (Resource Metrics). If other custom metrics need to be supported, typically prometheus-adapter is installed to serve as the implementation of HPA's Custom Metrics and External Metrics, providing monitoring data from Prometheus as custom metrics to HPA. In theory, HPA + prometheus-adapter can also achieve KEDA's functionality, but the implementation would be very cumbersome. For example, if you want to scale based on the count of pending tasks in a database task table, you would need to write and deploy an Exporter application to convert the statistics into Metrics exposed to Prometheus for collection, then prometheus-adapter would query Prometheus for the pending task count metric to decide whether to scale.
KEDA's emergence is mainly to solve the problem that HPA cannot scale based on flexible event sources. It has built-in dozens of common Scalers that can directly interface with various third-party applications, such as various open-source and cloud-managed relational databases, time-series databases, document databases, key-value stores, message queues, event buses, etc. It can also use Cron expressions for scheduled automatic scaling. Common scaling scenarios are basically covered, and if you find any unsupported scenarios, you can implement your own external Scaler to work with KEDA.
KEDA's Architecture
KEDA is not meant to replace HPA, but rather to complement or enhance it. In fact, KEDA often works together with HPA. This is KEDA's official architecture diagram:
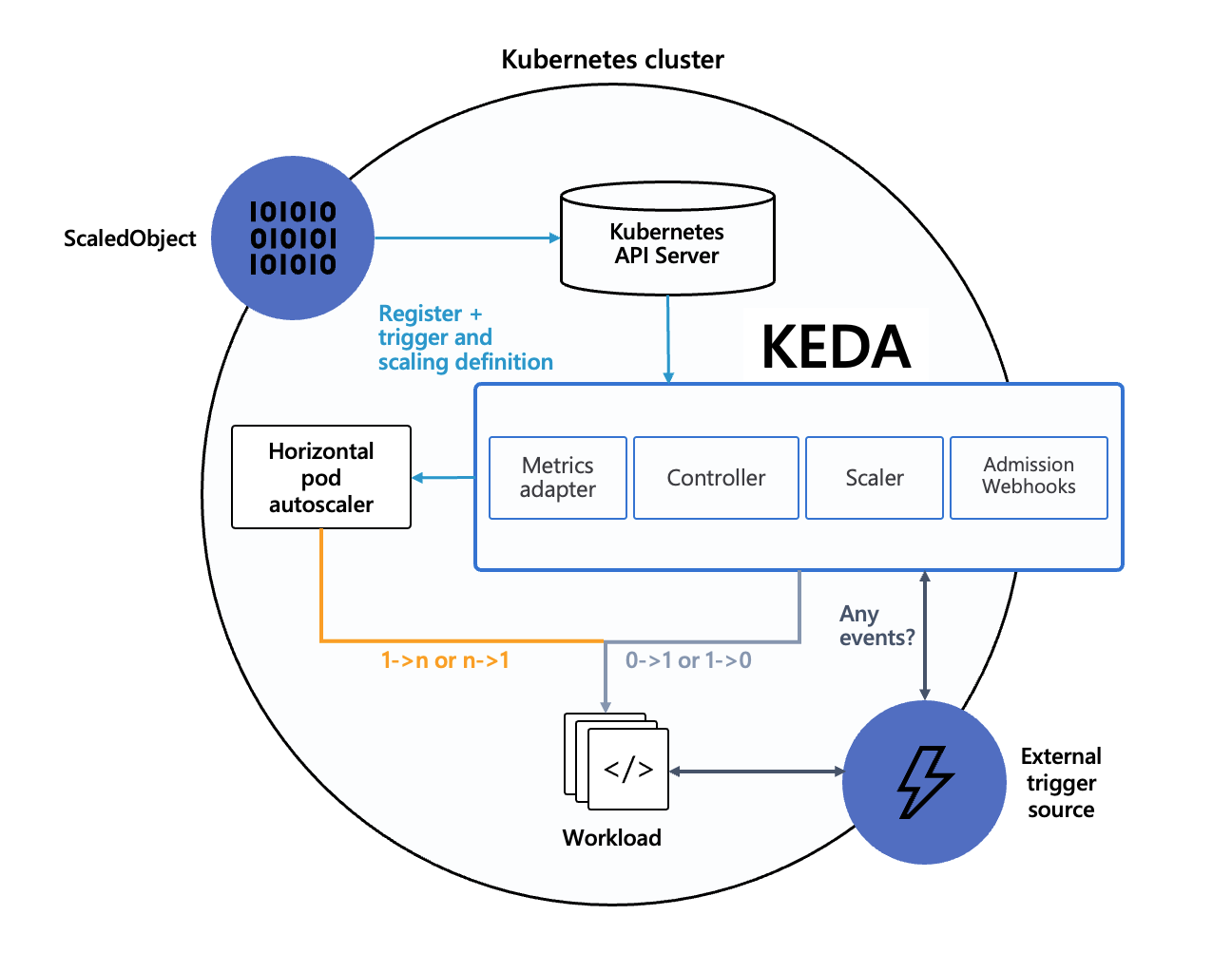
- When scaling the workload's replica count down to the idle replica count, or scaling up from the idle replica count, KEDA implements it by modifying the workload's replica count (idle replica count is less than
minReplicaCount, including 0, meaning it can scale to 0). - In other cases, scaling is implemented by HPA, which is automatically managed by KEDA. HPA uses External Metrics as the data source, and the External Metrics backend data is provided by KEDA.
- The core of KEDA's various Scalers is to expose data in External Metrics format for HPA. KEDA converts various external events into the required External Metrics data, ultimately enabling HPA to automatically scale through External Metrics data, directly reusing HPA's existing capabilities. So if you want to control the details of scaling behavior (such as fast scale-up, slow scale-down), you can directly configure HPA's
behaviorfield to achieve this (requires Kubernetes version >= 1.18).
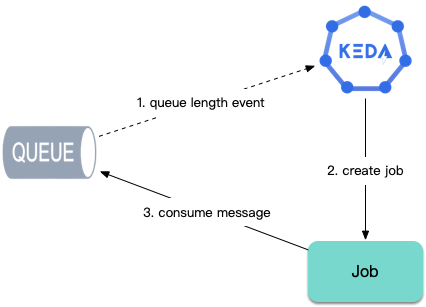
In addition to workload scaling, for job computing scenarios, KEDA can also automatically create Jobs based on the number of queued tasks for timely task processing:
Which Scenarios are Suitable for Using KEDA?
Below are scenarios suitable for using KEDA.
Multi-tier Microservice Invocations
In microservices, there are basically multi-tier invocation scenarios in business, where pressure is transmitted level by level. The following shows a common situation:

If using traditional HPA to scale based on load, after user traffic enters the cluster:
Deploy A's load increases, metric changes forceDeploy Ato scale.- After A scales, throughput increases, B receives pressure, metrics change again,
Deploy Bscales. - B's throughput increases, C receives pressure,
Deploy Cscales.
This level-by-level transmission process is not only slow but also dangerous: each level's scaling is directly triggered by CPU or memory spikes, and the possibility of being "overwhelmed" is widespread. This passive, lagging approach obviously has problems.
At this point, we can use KEDA to implement multi-tier fast scaling:
Deploy Acan scale based on its own load or QPS metrics recorded by the gateway.Deploy BandDeploy Ccan scale based onDeploy A's replica count (maintaining a certain ratio between service replica counts at each level).
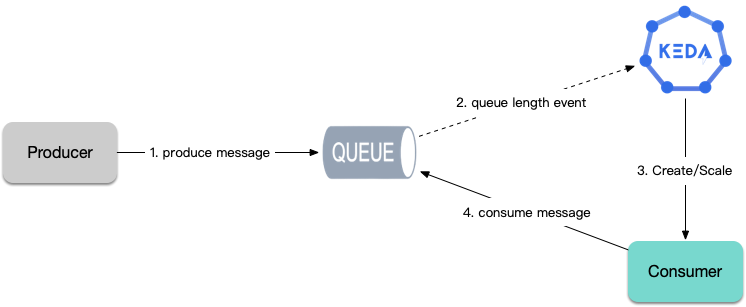
Task Execution (Producer and Consumer)
For long-running computational tasks such as data analysis, ETL, machine learning, etc., retrieving tasks from message queues or databases for execution, scaling based on task count, using HPA is not quite suitable. Using KEDA is very convenient - it can scale workloads based on the number of queued tasks, or automatically create Jobs to consume tasks.
Periodic Patterns
If business has periodic peak and valley characteristics, you can use KEDA to configure scheduled scaling, scaling in advance before peaks arrive, and slowly scaling down after they end.