Zero-Loss Traffic Upgrade for Core Applications
Business Scenario
For certain core applications (such as traffic gateways), you want to avoid failures caused by upgrades. When upgrading such core applications, you want to adopt very conservative upgrade strategies—preferring cumbersome operations over absolute risk control—ensuring that Pods to be upgraded are completely drained of traffic first, then manually rebuilt to trigger upgrades. After continuous real-world traffic canary testing for a period, if no issues are found, gradually expand the canary scope. During this process, any problems can be rolled back by reverting upgraded replicas.
The operation methods described in this article are very cumbersome and are only suitable for very conservative upgrade operations on extremely important applications.
Potential Failure Scenarios During Upgrades
The following lists some scenarios that may cause failures during upgrades:
- Imperfect implementation of application graceful termination logic, causing abnormal existing connections when Pods stop.
- Persistent long connections fail to disconnect, possibly exceeding
terminationGracePeriodSeconds, causing abnormal closure of existing connections when Pods stop. - New application versions may introduce hidden bugs or incompatible changes that health checks cannot detect, only discovered passively after deployment.
- CLB traffic draining and Pod stopping processes execute asynchronously in parallel. In extreme scenarios, Pods have already started graceful termination procedures and stopped accepting new connections, but CLB hasn't had time to drain traffic (modify weights), causing some new connections to be scheduled to this stopping Pod and not processed.
Zero-Loss Traffic Upgrade Methods
In TKE environments, you can use StatefulSet to deploy core applications, combined with TKE Service annotations to pre-drain traffic from specified Pods, then use StatefulSet's OnDelete update strategy to manually rebuild Pods for zero-loss traffic upgrades. The diagram below shows the general upgrade process:

Next, we'll describe specific operation methods.
Operation Steps
Create StatefulSet
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: nginx
spec:
replicas: 10
podManagementPolicy: Parallel
selector:
matchLabels:
app: nginx
serviceName: nginx
template:
metadata:
annotations:
tke.cloud.tencent.com/networks: tke-route-eni # Explicitly declare using VPC-CNI when mixing GlobalRouter and VPC-CNI
labels:
app: nginx
spec:
containers:
- image: nginx:1.25.3
imagePullPolicy: IfNotPresent
name: nginx
ports:
- containerPort: 80
name: http
protocol: TCP
resources: # Explicitly declare using VPC-CNI when mixing GlobalRouter and VPC-CNI
limits:
tke.cloud.tencent.com/eni-ip: "1"
requests:
tke.cloud.tencent.com/eni-ip: "1"
updateStrategy:
type: OnDelete # Important: Use manual rebuild to trigger upgrades instead of rolling updates
---
apiVersion: v1
kind: Service
metadata:
labels:
app: nginx
annotations:
service.cloud.tencent.com/direct-access: "true" # Important: Enable CLB direct-to-pod
name: nginx
spec:
ports:
- port: 80
protocol: TCP
targetPort: 80
selector:
app: nginx
type: LoadBalancer
- StatefulSet
updateStrategyusesOnDelete. - Ensure Pods use VPC-CNI network or are scheduled to super nodes (for easy CLB direct-to-pod enablement).
- Add Service annotation to enable CLB direct-to-pod.
Upgrade One by One
- First replace the image used by StatefulSet with the new image (the image version expected after upgrade).
kubectl set image statefulset/nginx nginx=nginx:1.25.4
- Increase StatefulSet replica count by 1, because during replica rebuild, replica count will decrease by 1. Pre-increasing by 1 replica avoids excessive average load on Pods during upgrade causing business abnormalities:
kubectl scale --replicas=11 statefulset/nginx
- Add annotation to Service:
service.cloud.tencent.com/lb-rs-weight: '{"defaultWeight":10,"groups":[{"key":{"proto":"TCP","port":80},"statefulSets":[{"name":"nginx","weights":[{"weight":0,"podIndexes":[0]}]}]}]}'
- In
key, fill in the port and protocol declared in Service. If multiple ports, add another configuration ingroupsarray (onlykeydifferent), like:service.cloud.tencent.com/lb-rs-weight: '{"defaultWeight":10,"groups":[{"key":{"proto":"TCP","port":80},"statefulSets":[{"name":"nginx","weights":[{"weight":0,"podIndexes":[0]}]}]},{"key":{"proto":"TCP","port":8080},"statefulSets":[{"name":"nginx","weights":[{"weight":0,"podIndexes":[0]}]}]}]}' - In
statefulSets, fill in StatefulSet name. - In
podIndexes, fill in Pod index planned for upgrade next, usually starting from 0. - Set
weightto 0, meaning drain traffic from Pod with this index (no new connections scheduled, wait for existing connections to end).
- In
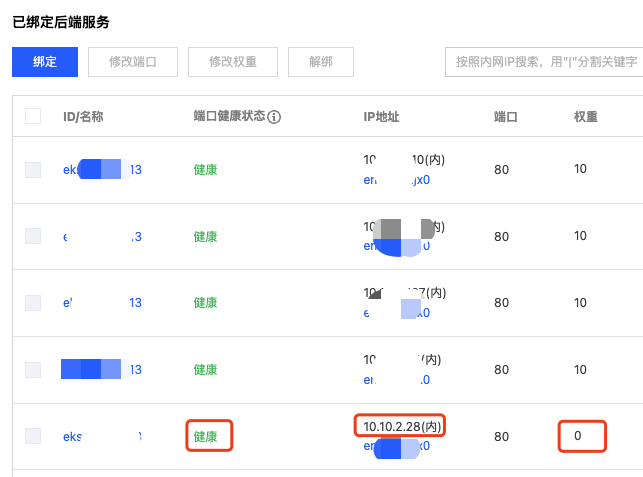
- Check the corresponding CLB's listener bound backend services in CLB console, confirm the Pod IP to be upgraded has traffic weight 0:

- Wait for existing connections and traffic to completely drop to zero, confirm in CLB monitoring page (filter by corresponding listener and backend service):

- Delete Pod planned for upgrade, triggering rebuild upgrade:
kubectl delete pod nginx-0
- Observe upgraded Pod's running status, image, and health status all meet expectations (validate with real-world traffic for a period, if abnormalities found, roll back image version and repeat steps 3~5 to roll back):
$ kubectl get pod -o wide nginx-0NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATESnginx-0 1/1 Running 0 86s 10.10.2.28 10.10.11.3 <none> 1/1$ kubectl get pod nginx-0 -o yaml | grep image:- image: nginx:1.25.4image: docker.io/library/nginx:1.25.4
- Modify
podIndexesin Service annotation, prepare to upgrade next Pod:service.cloud.tencent.com/lb-rs-weight: '{"defaultWeight":10,"groups":[{"key":{"proto":"TCP","port":80},"statefulSets":[{"name":"nginx","weights":[{"weight":0,"podIndexes":[1]}]}]}]}' - Repeat steps 3~7 until second-to-last replica upgrade completed.
- Delete
service.cloud.tencent.com/lb-rs-weightService annotation, restore all Pods' traffic weights. - Restore StatefulSet replica count (scale down last redundant replica):
At this point, upgrade completed.kubectl scale --replicas=10 statefulset/nginx
Batch Upgrade
If replica count is high and one-by-one upgrade is too cumbersome, you can batch upgrade, changing from upgrading 1 Pod at a time to upgrading multiple Pods at a time. Operation steps are basically the same as Upgrade One by One, just difference in number of Pods operated each time, mainly reflected in:
- Pre-expanded replica count and number of Pods deleted/rebuild each time changes from 1 to multiple.
podIndexesinservice.cloud.tencent.com/lb-rs-weightannotation changes from 1 to multiple, like (assuming upgrading 4 Pods each time):service.cloud.tencent.com/lb-rs-weight: '{"defaultWeight":10,"groups":[{"key":{"proto":"TCP","port":80},"statefulSets":[{"name":"nginx","weights":[{"weight":0,"podIndexes":[0,1,2,3]}]}]}]}'